Computation with Multilingual Word Lists
Compare the distribution of numbers of characters per word in different languages.
In[1]:=
languages = {"German", "English", "Italian", "Dutch", "Russian"};Get the available lists of words for those languages and collect them in an association.
In[2]:=
words = Association[# -> WordList[Language -> #] & /@ languages];Compute the lengths of each of those words.
In[3]:=
wordLengths = StringLength /@ words;These are the minimum and maximum lengths.
In[4]:=
MinMax /@ wordLengthsOut[4]=
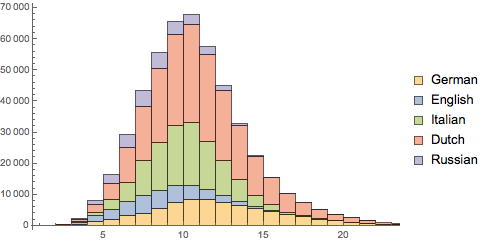
Show overlapped histograms of relative frequencies in each language. Russian and English have a higher fraction of shorter words, while Dutch and German have a clear tail of longer words.
In[5]:=
Histogram[wordLengths, Automatic, "PDF", ChartLegends -> Automatic]Out[5]=
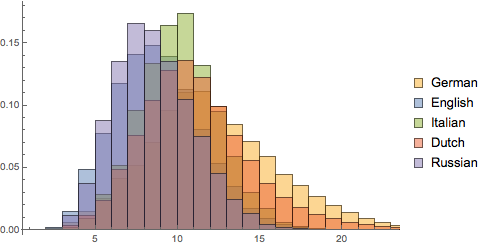
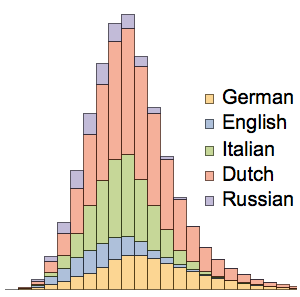
Combine the histograms to show total counts of lengths for all languages together.
In[6]:=
Histogram[wordLengths, ChartLegends -> Automatic,
ChartLayout -> "Stacked"]Out[6]=