Wolfram
Mathematica
8의 신기능: 매개 변수 추정 및 검정
◄
이전
|
다음
►
핵심 알고리즘
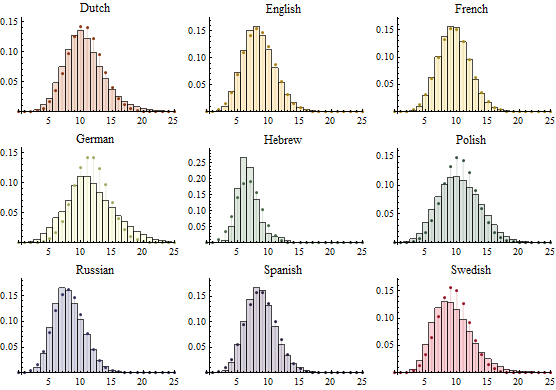
이항 분포에 의한 단어의 길이 모델링
다양한 언어에있어서 단어의 길이를 이항 분포에 적합하여 실제와 적합된 분포와 비교합니다.
In[1]:=
X
languages = {"Dutch", "English", "French", "German", "Hebrew", "Polish", "Russian", "Spanish", "Swedish"}; worddata = Table[StringLength /@ DictionaryLookup[{l, All}], {l, languages}];
In[2]:=
X
binom = Table[ EstimatedDistribution[i, BinomialDistribution[n, p], ParameterEstimator -> {"MaximumLikelihood", Method -> {"FindRoot", MaxIterations -> 1000}}], {i, worddata}];
In[3]:=
X
Partition[ Table[Show[ Histogram[worddata[[i]], {Range[25] - 1/2}, "PDF", PlotLabel -> languages[[i]], ChartStyle -> Directive[Opacity[.2], ColorData[35, i]]], DiscretePlot[PDF[binom[[i]], x], {x, 0, 25}, PlotRange -> All, PlotStyle -> {{PointSize[.02], Darker@ColorData[35, i]}}]], {i, Length[languages]}], 3] // Grid
Out[3]=