Основные алгоритмы
Моделирование длины слов с помощью биномиального распределения
Согласование длин слов в разных языках с биномиальным распределением и сравнение согласованного распределения с эмпирическим.
| In[1]:= |  X |
| In[2]:= |  X |
| In[3]:= |  X |
| Out[3]= | 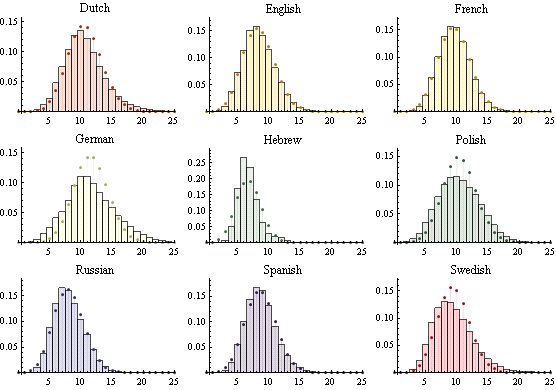 |
| Новое в системе Wolfram Mathematica 8: Оценивание параметров распределений и проверка статистических гипотез | ◄ предыдущая | следующая ► |
| In[1]:= | X |
| In[2]:= | X |
| In[3]:= | X |
| Out[3]= | |