英単語の頻度分布を求める
アメリカ合衆国憲法中の単語の出現数を数える.
In[1]:=
text = ExampleData[{"Text", "USConstitution"}, "Words"];
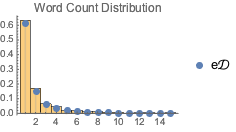
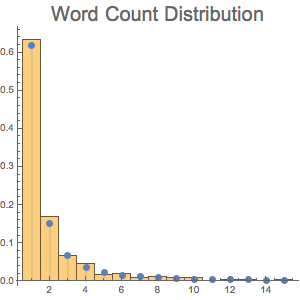
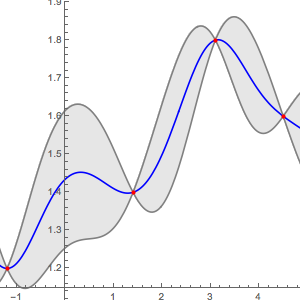
wordCount = Values[Counts[text]];単語の出現数の単純な分布を求める.
In[2]:=
e\[ScriptCapitalD] = FindDistribution[wordCount]Out[2]=
求められた分布と単語数を比較する.
完全なWolfram言語入力を表示する

Out[3]=