Buchstaben in einem Text
Japanisch verwendet drei unterschiedliche Zeichensysteme.
In[1]:=
Entity["Language", "Japanese"]["WritingScripts"]Out[1]=
Dies sind die Buchstaben der Hiragana-Silbenschrift.
In[2]:=
hiraganaCharacters =
Alphabet[Entity["WritingScript", "Hiragana::jx343"]]Out[2]=
Heben Sie die Hiragana-Zeichen im folgenden japanischen Text hervor.
In[3]:=

text = "汚れつちまつた悲しみに
今日も小雪の降りかかる
汚れつちまつた悲しみに
今日も風さへ吹きすぎる
汚れつちまつた悲しみは
たとへば狐の革裘
汚れつちまつた悲しみは
小雪のかかつてちぢこまる
汚れつちまつた悲しみは
なにのぞむなくねがふなく
汚れつちまつた悲しみは
倦怠のうちに死を夢む
汚れつちまつた悲しみに
いたいたしくも怖気づき
汚れつちまつた悲しみに
なすところもなく日は暮れ\[Ellipsis]\[Ellipsis]";Den kompletten Wolfram Language-Input zeigen

Out[4]=

Veranschaulichen Sie mit WordCloud die relative Häufigkeit der Hiragana-Zeichen im Text.
In[5]:=
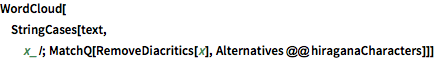
WordCloud[
StringCases[text,
x_ /; MatchQ[RemoveDiacritics[x],
Alternatives @@ hiraganaCharacters]]]Out[5]=