FileSystemScanを使ってシェークスピアの言語資料を作成する
この例では,シェークスピアの全作品のテキストファイルを含めるのにディレクトリを利用する.まずFileSystemMapで本のテキスト部分だけを集めてそれをインポートする.
完全なWolfram言語入力を表示する
In[2]:=

works = Values[
FileSystemMap[Import, FileNameJoin[{$HomeDirectory, "Books"}], 2,
FileNameForms -> "*.txt"][[1]]]Out[2]=
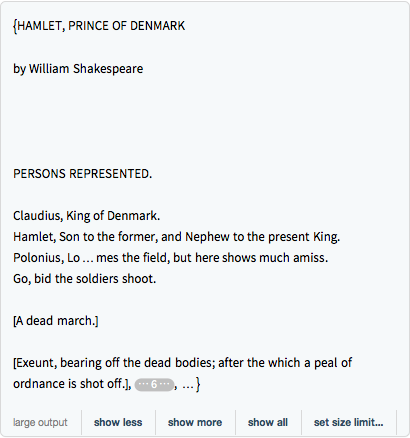
StringJoinを使って単一の言語資料を構築する.
In[3]:=
corpus = StringJoin[works]Out[3]=

これで言語資料を単一の検索可能な文字列として扱うことができるようになったので,高度なテキスト処理のアプリケーションも簡単に利用できる.繰返しや格の問題を取り除きながら,TextCasesを使ってこれらの作品にどの国が出てくるかを調べる.
In[4]:=
countries =
ToLowerCase[TextCases[corpus, "Country"]] // DeleteDuplicatesOut[4]=
完全なWolfram言語入力を表示する
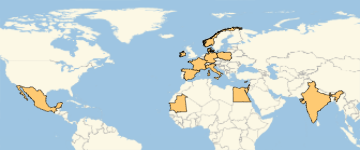
シェークスピアの作品に言及されている国々のGeoListPlotを構築する.
In[6]:=
GeoListPlot[Interpreter["Country"] /@ countries]Out[6]=