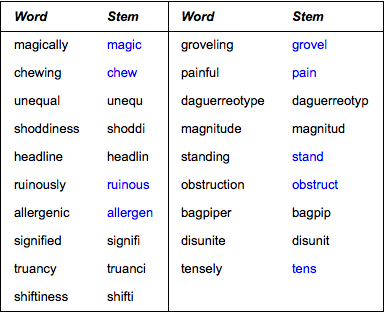
語幹を調べる
バージョン11には,単語の語幹を求め,複数語尾や屈折語尾等を削除する新たなツールが含まれている.単語の語幹はもとの意味を有しているが,それ自体は辞書に含まれないことが多い.この例では,その両方の場合を示す.
RandomWordでランダムな英単語30個のリストを生成する.
In[1]:=
Short[words = RandomWord[30]]Out[1]//Short=
WordStemで各単語の語幹を取り出す.
In[2]:=
Short[wordstems = WordStem[words]]Out[2]//Short=
語幹と形が等しい単語を除く.
In[3]:=
list = DeleteCases[Transpose[{words, wordstems}], {w_, w_}];語幹が新関数のDictionaryWordQで使われる英語の辞書に含まれる単語でもある場合には,それを青で強調する.
In[4]:=
list = Replace[
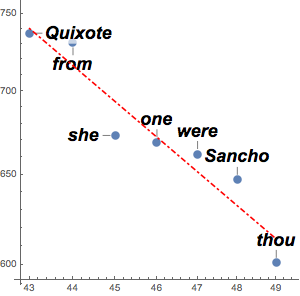
list, {w_, sw_?DictionaryWordQ} :> {w, Style[sw, Blue]}, {1}];各ペアをテキストの表で可視化する.
完全なWolfram言語入力を表示する

Out[5]=