文の構造を比較する
2つの文の構造は,それぞれの成分グラフを計算して処理することで,比べることができる.
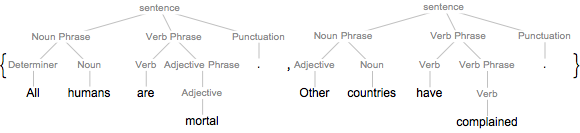
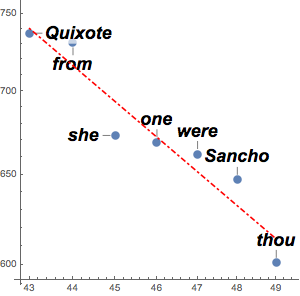
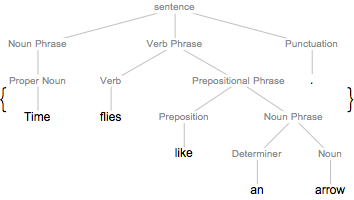
文の成分木をグラフとして表示する.
In[1]:=
graph = TextStructure["Time flies like an arrow.", "ConstituentGraph"]Out[1]=
グラフの全頂点間の距離の行列を計算する.
In[2]:=
distancemat1 = GraphDistanceMatrix[First[graph]];
MatrixForm[distancemat1]Out[2]//MatrixForm=

もう一つの文についても同様にする.
In[3]:=
graph2 = TextStructure["I fly in the sky.", "ConstituentGraph"];
distancemat2 = GraphDistanceMatrix[First[graph2]];2つの文の構造を,その距離行列を比較することで比較する.
In[4]:=
distancemat1 == distancemat2Out[4]=
この2つの文の構造は等しい.
異なる2つのWikipediaの記事の中で構造が等しい文を求める.まず,指定された単語数の文を抽出し,それぞれの成分グラフを生成する.
In[5]:=

processWikiPage[article_] :=
Select[TextCases[WikipediaData[article], "Sentences"],
WordCount[#] < 5 &];
genStructure[article_] :=
Flatten[TextStructure[#, "ConstituentGraph"] & /@
processWikiPage[article]];In[6]:=
phrasestruct1 = genStructure["Philosophy"];
phrasestruct2 = genStructure["History"];すべての距離行列を計算する.
In[7]:=
adj1 = GraphDistanceMatrix /@ phrasestruct1;
adj2 = GraphDistanceMatrix /@ phrasestruct2;異なる記事の文を2つずつ比較する.
In[8]:=
comparison = Outer[Equal, adj1, adj2, 1];次は構造が等しい文である.
In[9]:=

pickedSentences =
Flatten[Pick[Outer[List, phrasestruct1, phrasestruct2], comparison,
True], 1];次は最初のペアである.
In[10]:=
First[pickedSentences]Out[10]=