サブクエリを行う
SQLにおける非常に強力なテクニックに,データについてより複雑な質問をするためのサブクエリの使用がある.この例では,EntityFunctionをネストすることによって,相関性のあるサブクエリと相関性のないサブクエリがいかに簡単に生成できるかを示す.
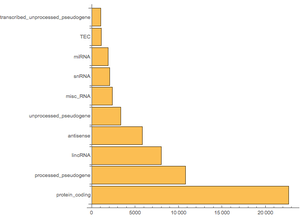
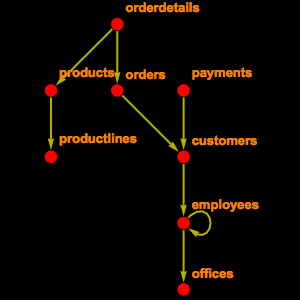
豊かな表構造を持つデータベースを例として登録する.
最大製品価格に近い製品について調べたいとする.まず集約を行い最大製品価格を調べ,その結果をクエリに使う方法を取ろうと考えるかもしれない.
この方法を使う問題は,2つのクエリを行う場合,データベースの別のユーザが予告なしに製品価格を変更してしまい,結果が使えないものになる可能性があるということである.
この問題を避けるためによく使われる解決策として,これらの補助的な計算をインラインで行い,計算が単一のトランザクション内で行われるようにする方法がある.
同じ式がEntityFunction式のボディ中に現れるようになったので,この式は確実にデータベースによって評価される.
SQLでよく使われるもう一つのパターンに,通常相関性のあるサブクエリと呼ばれるものがある.関数型プログラミングでは,これは,ネストされた純関数があり,その内側のものが外側のもののパラメータに依存するようにすることに等しい.ここでそのような例を段階を追って構築してみよう.
ここで知りたいのは,どの製品がその価格をメーカーの希望小売価格の$15以内の範囲に設定した製品を最も多く持つかということである.まず値 price の$15以内の価格を持つ製品を表すFilteredEntityClassを構築しなければならない.
次にその数を数えなければならない.これは特別な特性"EntityCount"を使って行える.
これを新しい特性として製品のクラスに加えることができる.
priceの値を100に固定したので,クエリは"products"に含まれるすべての実体について28の値を返す.
別の値が返されるようにしたい場合には,外側のEntityFunctionのスロットに依存する価格の値が必要である.
これで2つのネストしたEntityFunctionができ,最も内側のもののボディには両方のパラメータが含まれる.
それぞれの製品に対して異なる結果が得られるようになったことが確認できる.
この新しく作成した特性を使って結果をソートすることで,より豊かな結果を得ることができる.