公開のMySQLインスタンスに接続する
バイオインフォマティクスでは,非常に大きなデータ集合を含む,数多くの公開SQLの終点が存在する.この例では,いかに簡単にその1つに接続し,メモリでは非常に処理が困難である情報を素早く抽出することができるかを示す.
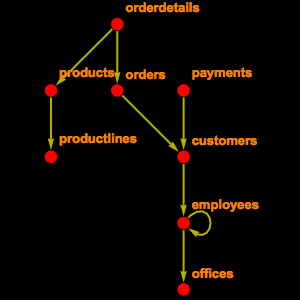
データを見るためには,ensemblプロジェクトが提供する公開の終点に接続し,2つの表についてスキーマ情報を抽出する.
次に,EntityStoreを構築する.
これを登録することができる.
計算は外部データベースに任せるので,すべては非常に高速で処理できる.
表には250万を超える行が含まれているが,これを1秒の何分の一の時間(ネットワークの往復時間も含める)で数えることができる.
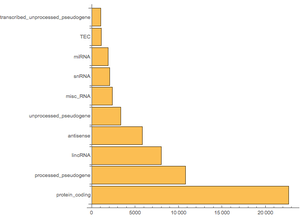
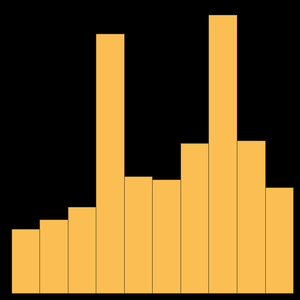
今度は,遺伝子の最もよくあるバイオタイプは何かについて調べてみよう.まず,バイオタイプごとにグループ分けし,遺伝子を数える.
次に,"count"特性でソートし,最も大きい10個だけを取る.
最後の2つは純粋に記号的な操作であることに注意する.クエリを実行するためにEntityValueを呼び出す.
データをプロットする.