Comience a utilizar las tecnologías Wolfram, o trabaje con nosotros para aplicar conocimientos computacionales a sus proyectos.
¿Tiene preguntas o comentarios? Contáctenos: 1-800-WOLFRAM, o envíenos un correo electrónico

Del primer capítulo de Modelling Financial Derivatives with Mathematica, por William Shaw
Cuando se expresa en términos matemáticos, el modelado de un instrumento derivado equivale a comprender el comportamiento de una función de varias variables con considerable detalle. Necesitamos saber no solo cómo calcular la función (el valor de una opción), sino también cómo comprender la sensibilidad del valor ante cambios en cualquiera de los parámetros de la función. Tal comprensión es más fiable cuando contamos tanto con una visión de sensibilidades locales, expresadas mediante derivadas parciales, como con una visión global, expresada mediante medios gráficos. Las derivadas parciales, expresadas en términos financieros, son los "griegos" del valor de la opción, y pueden ser variables de sensibilidad pasiva o parámetros activos de cobertura. Tales valoraciones de opciones pueden, en casos más simples, basarse en formas analíticas cerradas que involucran funciones especiales, o, en su defecto, pueden requerir cálculos numéricos intensivos que demandan una programación considerable.
Si se planteara desde cero qué tipo de sistema podría combinar la capacidad de:
i)manejar una gran cantidad de funciones especiales y realizar cálculo simbólico con ellas;
ii) gestionar cálculo numérico avanzado;
iii) permitir programar estructuras complejas;
iv) visualizar funciones en dos, tres o más dimensiones;
y hacerlo en una variedad de plataformas informáticas, se obtendría una lista muy corta de sistemas de modelado. Ni las hojas de cálculo ni C/C++ aparecerían en la lista, debido a su incapacidad fundamental para abordar el punto (i): el álgebra simbólica y el cálculo.
Una de las muy pocas soluciones completas a esta lista de requisitos es el sistema Mathematica. Originalmente subtitulado "A System for Doing Mathematics by Computer", es singularmente capaz como herramienta de modelado de derivados. En particular, la versión 3.0 y posteriores incluyen una funcionalidad numérica sustancialmente ampliada, y es capaz de realizar modelado numérico compilado de manera eficiente sobre estructuras grandes. Mathematica puede manejar no solo datos escalares, vectoriales y matriciales, sino también tensores de rango arbitrario; y su rendimiento escala bien hacia problemas grandes y realistas. Este libro es, en parte, una exploración de estas capacidades. También es una exploración de los algoritmos de valoración y de lo que puede fallar en ellos.
Este libro no es solo una exploración de algunos modelos bien conocidos. También exploraremos la resolución de la ecuación diferencial de Black-Scholes con la ayuda de Mathematica. Podemos explorar:
i)
separación de variables;
ii) métodos de similitud;
iii) funciones e imágenes de Green;
iv) métodos numéricos de diferencias finitas;
v) métodos numéricos de árboles;
vi) simulación de Monte Carlo
como técnicas de solución, todo dentro del entorno de Mathematica. Una comparación de estos enfoques y sus resultados es más que un ejercicio académico interesante, como veremos a continuación.
El riesgo de modelos puede surgir de diversas maneras. Dado un instrumento financiero, generalmente formulamos un proceso de valoración en tres etapas:
a)
descripción conceptual;
b) formulación matemática de la descripción conceptual;
c) resolución del modelo matemático mediante un proceso analítico y/o numérico.
Es posible cometer errores, o realizar suposiciones simplificadoras poco razonables, en cualquiera de estas tres etapas. Cada una de ellas da lugar a una forma de riesgo de modelo: el riesgo de que el proceso desde la lectura de un contrato hasta la obtención de resultados (valor justo, delta, gamma, …, volatilidad implícita) haya conducido a una respuesta incorrecta.
Este libro utiliza Mathematica para analizar de manera inteligente el tercer punto, que podríamos denominar riesgo de algoritmo. Podría pensarse que esto puede eliminarse simplemente siendo cuidadoso; la realidad es que los instrumentos derivados pueden presentar diversas formas de patología matemática que desafían nuestra intuición y afectan gravemente incluso a algoritmos estándar o avanzados. Este libro presenta algunos ejemplos conocidos y otros menos familiares de tales problemas.
Deseo enfatizar que no se trata simplemente de preocuparse por niveles de precisión inferiores al “nivel de ruido” de los operadores. Es posible obtener resultados gravemente incorrectos incluso cuando se cree estar actuando con cuidado. También considero que es responsabilidad de un equipo cuantitativo proporcionar respuestas lo más precisas posible a los equipos de trading y ventas. ¡Si ellos desean ajustar la respuesta en 50 puntos básicos, por cualquier razón, esa es su responsabilidad!
Una buena regla práctica es que, en general, se puede plantear el mismo problema a seis grupos diferentes y obtener al menos tres respuestas materialmente distintas. En modelado de derivados, normalmente se obtienen cuatro respuestas diferentes, especialmente si se incluye:
a) un entusiasta del análisis;
b) un entusiasta de los modelos de árboles;
c) un entusiasta de Monte Carlo;
d)
un entusiasta de diferencias finitas
Uso deliberadamente el término “entusiasta”. En una ocasión, en una reunión, me dijeron categóricamente que “había que usar martingalas—estos métodos de EDP están equivocados”, y conozco al menos un libro de EDP que casi no menciona la simulación, así como un excelente libro de simulación que describe el enfoque de EDP como “notorio”. En realidad, todos estos métodos deberían dar la misma respuesta cuando se aplican correctamente a un problema adecuado.
Las diferencias pequeñas pero molestas pueden surgir por discrepancias en aspectos como calendarios, unidades o capitalización continua frente a anual. Estas cuestiones deberían resolverse mediante coordinación del equipo de gestión de riesgos. Sin embargo, las diferencias reales entre modelos requieren un enfoque mucho más disciplinado.
La única forma de resolver diferencias significativas es realizar algún tipo de estudio de verificación. Esto puede hacerse en diversas maneras, entre las cuales las dos más importantes son:
a) Comparación de sistemas de modelado con alguna forma de referencia absolutamente precisa (típicamente solo disponible para modelos más simples, pero debemos verificar que los algoritmos complejos funcionen correctamente cuando se especializan en casos simples);
b) Intercomparación de modelos y códigos cuando se aplican a instrumentos complejos.
La idea básica es definir un conjunto integral de problemas de prueba, y ejecutar un modelo de referencia y sistemas operativos frente a tantos otros como estén disponibles.
En otros campos de estudio este es en realidad un proceso común. Espero que este texto fomente esfuerzos similares dentro de la comunidad de modelado de derivados.
Los requisitos esenciales de tal enfoque incluyen la duplicación de esfuerzos. Mi opinión es que ningún resultado debe creerse a menos que pueda justificarse como el resultado de al menos dos esfuerzos de modelado diferentes (o al menos que el mismo sistema haya pasado por un estudio de intercomparación o de referencia en el pasado, y que ello haya sido documentado). ¡Esto generalmente no es lo que la administración encargada de la asignación de recursos quiere oír! El punto es que la calidad solo se logra mediante pruebas y evaluaciones cuidadosas y críticas.
En los últimos años han surgido una serie de herramientas que amplían la utilidad de las computadoras desde el “cálculo numérico” al ámbito de realizar álgebra y cálculo. Los sistemas más maduros combinan dicha capacidad simbólica con algoritmos numéricos avanzados, gráficos en 2D, 3D y animados, y un entorno de programación. Tales herramientas son particularmente relevantes para el área de modelado y prueba de derivados debido a
a) el hecho de que tienen rutinas integradas para la mayoría de las operaciones básicas comunes;
b) la capacidad de realizar cálculo con funciones simples y complejas puede eliminar muchos de los problemas de calcular los griegos;
c) la capacidad de comparar modelos simbólicos analíticos directamente con los resultados de un algoritmo numérico;
d)
la capacidad de visualizar los resultados, y literalmente ver los errores si los hay.
Es mi firme creencia que a largo plazo tales sistemas híbridos simbólico-numérico-gráficos reemplazarán las hojas de cálculo y lenguajes como C o C++ para el modelado de derivados. Su principal ventaja radica en la provisión de capacidades simbólicas avanzadas. En un sistema basado numéricamente las únicas dos formas de diferenciar para obtener un griego como delta son a) calcular la derivada en papel y codificarla, b) calcular el valor de una opción para uno o dos valores vecinos del parámetro y tomar diferencias. Ambos enfoques tienen desventajas, y el potencial de error humano en la etapa de lápiz y papel, y errores numéricos derivados de problemas de diferenciación numérica. En cambio, ahora podemos pedirle a la computadora que realice la diferenciación por nosotros. Tales entornos simbólicos, ricos en bibliotecas de funciones especiales, pueden reducir drásticamente el tiempo de desarrollo por debajo del de sistemas de hojas de cálculo o C/C++. Además, en el contexto de pruebas y verificación, ofrecen un entorno integrado simple donde un modelo numérico puede compararse directamente con su forma exacta. Y me refiero a exacta: los sistemas actuales pueden realizar aritmética de precisión arbitraria con facilidad, y pueden hacerlo con “funciones especiales” complicadas. Las versiones más recientes de estos sistemas, como es el caso de Mathematica 3.0 o posteriores, también pueden producir material matemático con formato tipográfico, de modo que puede escribir su código, escribir un modelo matemático, probarlos, representar los resultados y producir un informe para gestión de riesgos/trading/organismos regulatorios—todo dentro de un mismo entorno.
Existen muchos problemas con los entornos de hojas de cálculo. Una discusión extensa de los problemas es presentada por R. Miller (1990) en el Capítulo 1 de su texto, Computer-Aided Financial Analysis, donde expone varios principios a los que deberían ajustarse los entornos de modelado financiero, y explica por qué las hojas de cálculo no los cumplen. Mi propia interpretación simplista de las opiniones de Miller (es decir, mi propio prejuicio) es que las hojas de cálculo son la mejor manera inventada hasta ahora de mezclar datos de entrada, modelos y datos de salida. Más seriamente, su famosa capacidad para realizar cálculos de “qué pasaría si” es al mismo tiempo errónea y engañosa. En el contexto particular del modelado de derivados, el modelado de los griegos dentro de hojas de cálculo mediante la revaloración para valores vecinos de los parámetros es una aberración. El punto es que se debe usar cálculo exacto siempre que sea posible para extraer derivadas parciales. Como señala Miller, el concepto de “qué pasaría si” también está limitado a variaciones numéricas. Queremos un sistema donde también podamos variar propiedades estructurales (“qué pasaría si fuera americana en lugar de europea”). Esto conduce de manera bastante natural al deseo de un enfoque orientado a objetos.
Hay una virtud del entorno de hojas de cálculo, y es la interfaz de usuario tabular. No hay duda de que para instrumentos que requieren un pequeño número de parámetros de entrada y salida, tal tabla de datos para varios instrumentos es extremadamente útil. Sin embargo, incluso las virtudes de interfaz de las hojas de cálculo se ven forzadas por las complejidades de instrumentos como los bonos convertibles. La información relevante para uno de estos bonos puede requerir fácilmente varias hojas interconectadas.
No es por casualidad, en mi opinión, que el acrónimo en español para programación orientada a objetos sea POO, en lugar de OOP. C++ se ha arraigado como sistema de modelado en muchas instituciones financieras. En opinión del autor, el trabajo de un “Quant” es analizar, probar y valorar instrumentos financieros lo más rápida y fiablemente posible para responder a las necesidades de trading. No hay mayor desperdicio del tiempo de un Quant que tener que escribir y depurar algoritmos en C++, y mucho menos, Dios no lo quiera, gastar aún más energía incrustándolos en una hoja de cálculo. Si se necesita realizar un modelo altamente intensivo numéricamente para el cual un sistema como Mathematica pueda, al menos por ahora, ser inadecuado, la solución, por el momento, es utilizar un sistema diseñado para la tarea, como FORTRAN 90 altamente optimizado. Las objeciones a Mathematica basadas en la velocidad de ejecución son ahora esencialmente irrelevantes debido a las mejoras en CPUs de alta velocidad y bajo costo, y a la mayor eficiencia del entorno numérico compilado interno de Mathematica. Los sistemas en C++ son mucho más lentos de escribir, lentos de compilar, y su ventaja en tiempo de ejecución es ahora marginal. El gran sueño de los gestores de sistemas es que, una vez completado el esfuerzo de construir una biblioteca de rutinas centrales en C++, los modeladores puedan construir nuevos algoritmos rápidamente. Lamentablemente, esto es solo un sueño. Los proyectos OOP misteriosamente parecen requerir aumentos masivos en personal y presupuestos, y sin embargo siguen siendo los favoritos de los gestores de sistemas.
Esto NO quiere decir que un enfoque orientado a objetos sea una mala idea—el problema es encaminar nuevamente el sueño. Mi opinión es que el sistema base para el desarrollo de derivados orientado a objetos debería estar al nivel de un sistema como Mathematica, donde existe una capacidad simbólica y ya hay una enorme colección de objetos básicos con sus matemáticas resueltas. Una buena pregunta para hacer a un equipo de derivados basado en OOP es cuánto tiempo han desperdiciado codificando interpolación, distribuciones normales, griegos y todo tipo de funciones especiales y capacidades que ya existen en Mathematica. En este texto no he intentado un enfoque completamente orientado a objetos. Mi enfoque ha sido asegurar que las respuestas sean correctas. Dejo a otros adoptar algunos de estos métodos y algoritmos en un entorno más estructurado.
El poder de Mathematica como herramienta de investigación se hace evidente en este contexto. Podemos definir una serie de problemas de prueba y usar las capacidades de funciones especiales de Mathematica para caracterizar la solución exactamente, utilizando la aritmética de precisión infinita de Mathematica para obtener resultados con tanta precisión como deseemos. A continuación utilizamos las capacidades de cálculo simbólico de Mathematica para definir los griegos mediante diferenciación. Luego, para modelos más complejos, construimos modelos de árboles, Monte Carlo y diferencias finitas dentro de Mathematica. Después realizamos una comparación, dentro de Mathematica, entre estas formas analíticas y las soluciones numéricas, y las soluciones de otros sistemas de la empresa. Los resultados se comparan, y las razones de cualquier diferencia u otros problemas se exploran y se resuelven.
A aquellos que consideren mis comentarios sobre sistemas de modelado tradicionales como extremos o mal informados, les planteo este desafío. Existe ahora una solución exacta para la opción asiática aritmética promediada continuamente. Este es el modelo de Geman-Yor descrito en el Capítulo 10. Logré implementarlo en Mathematica y probarlo en un total de seis horas. A cualquiera que pueda implementarlo en C++ y obtener resultados precisos a 4 decimales, le ofrezco una botella de champán de calidad vintage. Si puede hacerlo en menos de 40 horas de programación, dos botellas. A cualquiera que pueda hacerlo funcionar con la misma precisión únicamente en una hoja de cálculo, le ofrezco una caja de buen vino tinto, sin importar cuánto tiempo tome.
A manera de ilustrar algo que es fácil de explorar en un sistema como Mathematica, presentamos un ejemplo de cómo se puede investigar un tema dentro de un sistema que combina modelos simbólicos y gráficos. El tema elegido es la “volatilidad implícita”, y el objetivo es dejar claro cuán pocas veces este concepto tiene sentido. Esto es importante tanto desde el punto de vista matemático, ya que debemos observar cuándo una función no puede invertirse porque es “muchos a uno”, como desde el punto de vista del trading—la volatilidad implícita se utiliza a menudo como un parámetro clave.
Los operadores insisten en solicitar volatilidades implícitas. Se les puede dar un número, pero puede no tener ningún sentido. O más bien, se puede introducir un precio de mercado de un instrumento en un sistema que realiza todo tipo de cálculos sofisticados para encontrar la volatilidad consistente con el precio de mercado dados los demás datos, y esta volatilidad puede no tener sentido en absoluto. Es una buena idea enumerar la situación favorable y todos los problemas que pueden surgir. Enfatizo que estos no son problemas vinculados a un método de solución particular, como Newton-Raphson o bisección, donde pueden surgir problemas específicos del método. Son cuestiones de principio que causarán problemas independientemente de la técnica de solución empleada.
Cuando la valoración es una función monótona de la volatilidad (estrictamente creciente o decreciente), normalmente no hay problema. El caso simple de una opción de compra europea estándar, como fue desarrollado por Black y Scholes (1973), entra en esta categoría. Construyamos un modelo simbólico de esta opción y grafiquemos el valor como función de la volatilidad—aprovechamos para mostrar lo fácil que es escribir un modelo en un sistema simbólico como Mathematica.

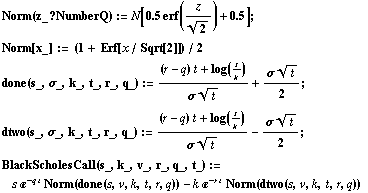
Representamos el valor de la opción como función de la volatilidad, para una opción donde el precio de ejercicio es 10, el subyacente es 11, para una opción call europea estándar con un año hasta el vencimiento, tasa libre de riesgo del 5% (capitalización continua) y sin dividendos.
![[Graphics:Ch1htmlgr3.gif]](/customer-stories/images/text/Ch1htmlgr3.gif)
![[Graphics:Ch1htmlgr4.gif]](/customer-stories/images/text/Ch1htmlgr4.gif)
También podemos construir rápidamente un calculador de volatilidad implícita (FindRoot es un solucionador combinado de Newton-Raphson/Secante).
BlackScholesCallImpVol[s_,k_,r_,q_,t_,price_] :3Dsd /. FindRoot[BlackScholesCall[s,k, sd, r, q, t]3D3Dprice,{sd,0.2}];
Debido a que la función es estrictamente creciente, obtenemos una correspondencia uno a uno entre precios y volatilidades.
![[Graphics:Ch1htmlgr5.gif]](/customer-stories/images/text/Ch1htmlgr5.gif)
![[Graphics:Ch1htmlgr6.gif]](/customer-stories/images/text/Ch1htmlgr6.gif)
![[Graphics:Ch1htmlgr7.gif]](/customer-stories/images/text/Ch1htmlgr7.gif)
![[Graphics:Ch1htmlgr8.gif]](/customer-stories/images/text/Ch1htmlgr8.gif)
Los resultados son estables—un pequeño cambio en el precio de mercado provoca un pequeño cambio en las volatilidades implícitas.
![[Graphics:Ch1htmlgr9.gif]](/customer-stories/images/text/Ch1htmlgr9.gif)
![[Graphics:Ch1htmlgr10.gif]](/customer-stories/images/text/Ch1htmlgr10.gif)
No se necesita mucho para arruinar el cálculo de la volatilidad implícita. Añadamos un efecto de dilución al modelo de Black-Scholes, proporcionando un modelo simple para un warrant. Este es uno de los modelos de valoración de warrants más simples discutidos por Lauterbach y Schultz (1990).
![[Graphics:Ch1htmlgr11.gif]](/customer-stories/images/text/Ch1htmlgr11.gif)
Cuando representamos el resultado de precio frente a volatilidad, vemos que hay una región monótona para volatilidades mayores, pero que la curva se vuelve muy plana cuando la volatilidad cae por debajo del 20%. La inversión correspondiente para la volatilidad implícita entonces se vuelve inestable o imposible.
![[Graphics:Ch1htmlgr12.gif]](/customer-stories/images/text/Ch1htmlgr12.gif)
![[Graphics:Ch1htmlgr13.gif]](/customer-stories/images/text/Ch1htmlgr13.gif)
No es necesario complicar mucho la opción para entrar en problemas. Una opción de barrera simple mostrará el fenómeno de que existen dos volatilidades consistentes con una valoración dada. Supongamos una opción call “up and out” donde el subyacente está en 45, el precio de ejercicio en 50 y la barrera de knockout en 60. A medida que aumentamos la volatilidad desde un valor muy bajo, el valor de la opción aumenta. Luego, a medida que la volatilidad aumenta más, la probabilidad de knockout aumenta, reduciendo el valor de la opción. Ajustando un reembolso podemos lograr que haya tres soluciones para un pequeño rango de precios de mercado de la opción. El modelo de barreras que utilizamos es el modelo analítico desarrollado por Rubenstein y Reiner (1991)—nuevamente construido en Mathematica, aunque aquí omitimos los detalles del modelo simbólico—se presentan en el Capítulo 8. Los dos grafos siguientes muestran casos en los cuales hay dos y tres volatilidades implícitas, respectivamente.
![[Graphics:Ch1htmlgr14.gif]](/customer-stories/images/text/Ch1htmlgr14.gif)
![[Graphics:Ch1htmlgr15.gif]](/customer-stories/images/text/Ch1htmlgr15.gif)
![[Graphics:Ch1htmlgr16.gif]](/customer-stories/images/text/Ch1htmlgr16.gif)
![[Graphics:Ch1htmlgr17.gif]](/customer-stories/images/text/Ch1htmlgr17.gif)
En otras palabras, vega es positivo salvo en un intervalo en el que es negativo.
![[Graphics:Ch1htmlgr18.gif]](/customer-stories/images/text/Ch1htmlgr18.gif)
![[Graphics:Ch1htmlgr19.gif]](/customer-stories/images/text/Ch1htmlgr19.gif)
En el Capítulo 8 se verá cómo vega se define mediante diferenciación elemental utilizando el operador “D” de Mathematica.
Si desea ver cuán mal puede llegar a ser, una opción de barrera puede presentar situaciones aún más interesantes. Si consideramos una opción put “up and out”, donde el precio de ejercicio coincide con la barrera, y hacemos coincidir la tasa libre de riesgo y el rendimiento por dividendos, podemos obtener un vega exactamente cero (y gamma cero también). Así, si el precio de mercado coincide con el valor calculado, puede tener la volatilidad implícita que desee. De lo contrario, no hay volatilidad implícita.
Plot3D[UpAndOutPut[0, S, 50, 50, vol,0.1, 0.1, 1],
{S, 30, 50},
{vol, 0.05, 0.4 }, PlotRange -> {-0.01, 0.01}, PlotPoints ->
40];
![[Graphics:Ch1htmlgr20.gif]](/customer-stories/images/text/Ch1htmlgr20.gif)
Debería sentirse agradecido de que esto sea todo lo que puede salir mal. Afortunadamente, los modeladores de derivados tienden a usar números reales. En teoría de funciones complejas, Newton-Raphson y otros métodos iterativos son famosos por generar fractales y comportamientos caóticos. Pero es buena idea evitar reportar volatilidades implícitas a menos que se tenga una comprensión firme de las características del instrumento. Solo las opciones más simples se comportan bien en este sentido. Más generalmente, no se deben reportar resultados de volatilidad implícita a menos que primero se haya verificado que el valor absoluto de vega esté acotado lejos de cero. De lo contrario, la volatilidad implícita es, en el mejor de los casos, inestable y posiblemente indefinida—en tales casos no debería reportarse.
Este pequeño estudio ha ilustrado varios puntos sobre el uso de Mathematica:
a) Se pueden construir modelos simbólicos muy rápidamente;
b) Los griegos pueden investigarse mediante diferenciación simbólica;
c) Podemos visualizar nuestros modelos utilizando gráficos en dos y tres dimensiones;
d) Podemos exponer situaciones peculiares con relativa facilidad.
Más adelante en este libro veremos cómo la exposición de problemas significativos puede extenderse a procesos intensamente numéricos.
Por ahora volvemos a los principios básicos. En los próximos tres capítulos sentamos las bases de
a) Usar Mathematica;
b)
b) Matemáticas financieras para la valoración de derivados;
c) c) Las matemáticas para resolver ecuaciones diferenciales parciales (la EDP de Black-Scholes).
Vivimos en un mundo donde la ciencia cuantitativa aplicada en general, y el modelado financiero en particular, está cada vez más dominado por el modelado puramente numérico. La opinión del autor es que el enfoque analítico está siendo eclipsado de manera inapropiada por un enfoque bastante irreflexivo que consiste en arrojar modelos a una computadora y ver qué números salen.
Esta no es la mejor manera de usar las computadoras. Buscamos comprender el comportamiento de sistemas complejos, y esto se logra mejor intentando primero un tratamiento analítico. Esto primero enfoca nuestra intuición, y nos proporciona casos de prueba contra los cuales verificar cuando finalmente adoptamos un enfoque puramente numérico. Los sistemas de álgebra simbólica como Mathematica nos permiten extender el enfoque analítico a sistemas mucho más complejos. El enfoque numérico siempre debería ser el último recurso absoluto, y luego debe verificarse extensamente frente a los resultados analíticos. Este es el principio rector detrás del enfoque adoptado por este texto.
Black, F. and Scholes, M., Journal of Political Economy, Vol.
81, p. 637, 1973. (Reprinted and widely accessible as Chapter 1 of
"Vasicek and Beyond", ed. Hughston, Risk Publications,
1996).
Lauterbach, B. and Schultz, P., Journal of Finance,
XLV, 4, p. 1181, September 1990.
Miller, R.M. , Computer-Aided
Financial Analysis, Addison-Wesley, 1990.
Rubenstein, M. and
Reiner, E. Breaking Down the Barriers, RISK Magazine, September 1991.