텍스트 내의 문자
일본어는 세가지 다른 문자 체계를 사용합니다.
In[1]:=
Entity["Language", "Japanese"]["WritingScripts"]Out[1]=
다음은 히라가나입니다.
In[2]:=
hiraganaCharacters =
Alphabet[Entity["WritingScript", "Hiragana::jx343"]]Out[2]=
다음의 일본어 텍스트 중 히라가나를 하이라이트합니다.
In[3]:=

text = "汚れつちまつた悲しみに
今日も小雪の降りかかる
汚れつちまつた悲しみに
今日も風さへ吹きすぎる
汚れつちまつた悲しみは
たとへば狐の革裘
汚れつちまつた悲しみは
小雪のかかつてちぢこまる
汚れつちまつた悲しみは
なにのぞむなくねがふなく
汚れつちまつた悲しみは
倦怠のうちに死を夢む
汚れつちまつた悲しみに
いたいたしくも怖気づき
汚れつちまつた悲しみに
なすところもなく日は暮れ\[Ellipsis]\[Ellipsis]";전체 Wolfram 언어 입력 표시하기

Out[4]=

WordCloud를 사용하여 텍스트 중 히라가나의 상대적인 빈도를 나타냅니다.
In[5]:=
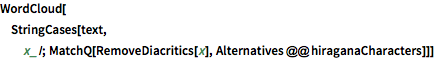
WordCloud[
StringCases[text,
x_ /; MatchQ[RemoveDiacritics[x],
Alternatives @@ hiraganaCharacters]]]Out[5]=