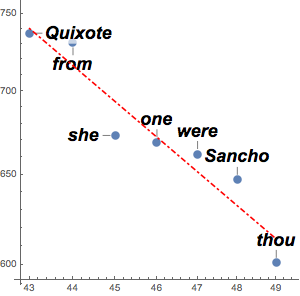
テキスト中の国実体を求める
TextCasesの別の使い方を取り上げる.ここでは,与えられたテキスト中の国を認識するためにこの関数を使う.
歴史的な3つの時代のリストを作る.
In[1]:=

periods = {Entity["HistoricalPeriod", "EuropeanRenaissance"],
Entity["HistoricalPeriod", "AgeEnlightenment"],
Entity["HistoricalPeriod", "IndustrialRevolution"]};それぞれの名前を取り出す.
In[2]:=
names = CommonName[periods]Out[2]=
WikipediaDataを使ってそれぞれの歴史的時代のページ中のテキストを取り出す.
In[3]:=
wikipages = WikipediaData /@ names;TextCasesを使って各ページで言及された国を,重複するものは削除して取り出す.
In[4]:=
countries =
DeleteDuplicates[TextCases[#, "Country" -> "Interpretation"]] & /@
wikipages;例えば,以下の国々はヨーロッパの啓蒙時代のページに現れるものである.
In[5]:=
First[countries]Out[5]=

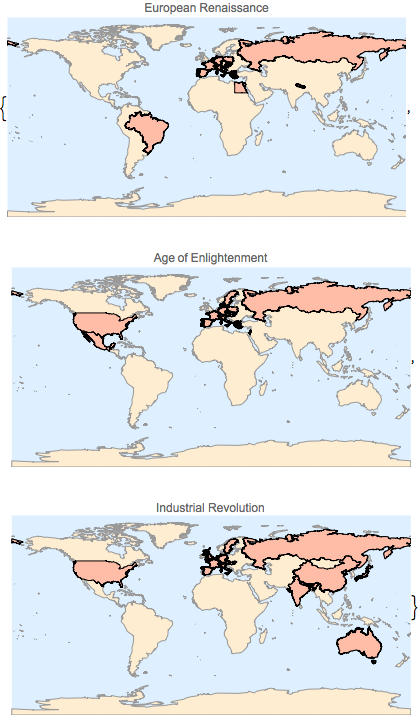
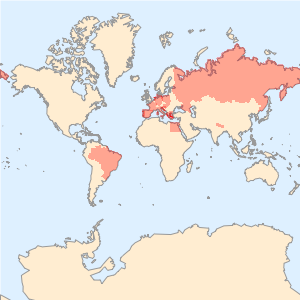
各記事で言及された国をそれぞれの世界地図上にプロットする.
完全なWolfram言語入力を表示する

Out[6]=