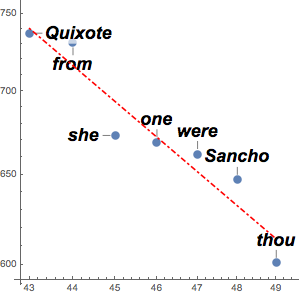
找出文本中的国家实体
该范例显示了 TextCases 的另一种用法,用其识别给定文本中的国家.
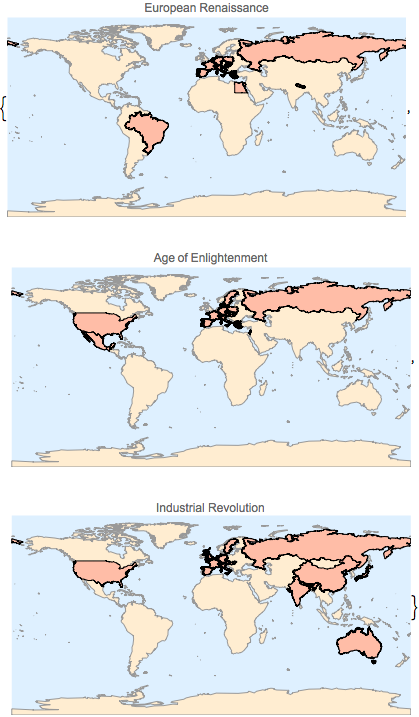
构建三个历史时期的列表.
In[1]:=

periods = {Entity["HistoricalPeriod", "EuropeanRenaissance"],
Entity["HistoricalPeriod", "AgeEnlightenment"],
Entity["HistoricalPeriod", "IndustrialRevolution"]};提取其相对应名称.
In[2]:=
names = CommonName[periods]Out[2]=
用 WikipediaData 提取每个历史时期页面的文本.
In[3]:=
wikipages = WikipediaData /@ names;用 TextCases 提取这些页面中提到的国家,并删除重复.
In[4]:=
countries =
DeleteDuplicates[TextCases[#, "Country" -> "Interpretation"]] & /@
wikipages;例如,以下为在欧洲文艺复兴时期页面中找到的国家.
In[5]:=
First[countries]Out[5]=

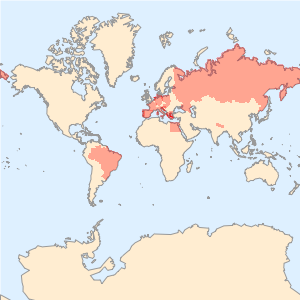
将每个文章中提到的国家分别绘制在世界地图上.
显示完整的 Wolfram 语言输入

Out[6]=