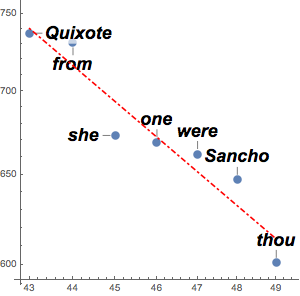
Нахождение названий стран в текстах
Данный пример демонстрирует иное применение TextCases, в данном случае для того, чтобы распознать страны в заданном тексте.
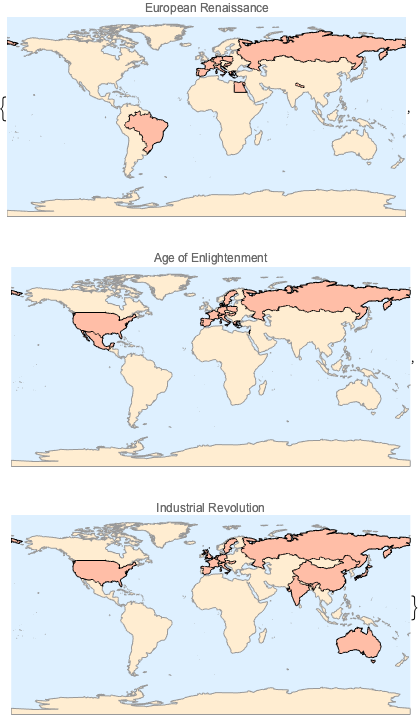
Создайте список из трёх исторических периодов.
In[1]:=

periods = {Entity["HistoricalPeriod", "EuropeanRenaissance"],
Entity["HistoricalPeriod", "AgeEnlightenment"],
Entity["HistoricalPeriod", "IndustrialRevolution"]};Извлеките соответствующие названия.
In[2]:=
names = CommonName[periods]Out[2]=
Используйте WikipediaData для получения страницы с текстом для каждого исторического периода.
In[3]:=
wikipages = WikipediaData /@ names;Используйте TextCases для получения названия стран, упомянутых на каждой странице, попутно удаляя дублированные упоминания.
In[4]:=
countries =
DeleteDuplicates[TextCases[#, "Country" -> "Interpretation"]] & /@
wikipages;Например, ниже представлены страны, присутствующие на странице о европейском Ренессансе.
In[5]:=
First[countries]Out[5]=

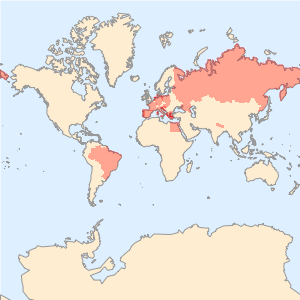
Графически изобразите на соответствующих картах мира страны, упомянутые в каждой статье.
код на языке Wolfram Language целиком

Out[6]=