Zipf's Law
Zipf's law states that in a corpus of a language, the frequency of a word is inversely proportional to its rank in the global list of words after sorting by decreasing frequency. This example demonstrates the law with the set of words in Miguel de Cervantes's novel Don Quixote, using the new functions WordCount and WordCounts.
ExampleData contains the text in Spanish of the first volume of Don Quixote.
textSpanish = ExampleData[{"Text", "DonQuixoteISpanish"}];The sample considered here is comprised of more than 180,000 words.
WordCount[textSpanish]The counts of each distinct word are given as an association by WordCounts. The result is already sorted by decreasing counts.
association = WordCounts[textSpanish];Take[association, 10]Take the counts of the first 1,000 most frequent words.
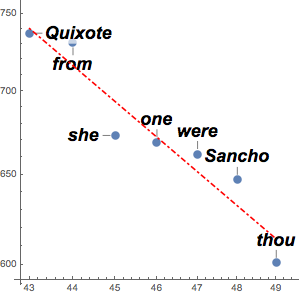
counts = Take[Values@association, 1000];To approximate those counts with a power law, take logarithms to use linear fitting. Zipf's law asserts that the exponent should be approximately 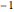 , and the result is a close value.
, and the result is a close value.
f[x_] = Fit[Log[Transpose[{Range[1000], counts}]], {1, x}, x]Visualize the fit together with the actual data.

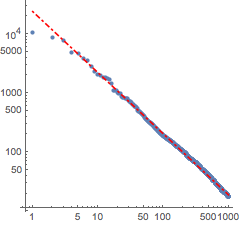
Zipf's law holds in any language, so the same computation is performed with the English version of Don Quixote.
textEnglish = ExampleData[{"Text", "DonQuixoteIEnglish"}];associationEnglish = WordCounts[textEnglish];
countsEnglish = Take[Values@associationEnglish, 1000];Take[associationEnglish, 10]Again, the exponent found is close to 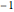 .
.
Fit[Log[Transpose[{Range[1000], countsEnglish}]], {1, x}, x]