Закон Ципфа
Закон Ципфа утверждает, что при рассмотрении всего состава языка частота слова обратно пропорциональна его порядковому номеру в полном списке слов, упорядоченному по убыванию частоты их использования. Данный пример демонстрирует закон для набора слов из романа Мигеля Сервантеса "Дон Кихот" с использованием новыx функций WordCount и WordCounts.
ExampleData содержит текст первого тома "Дон Кихота" на испанском языке.
textSpanish = ExampleData[{"Text", "DonQuixoteISpanish"}];Представленный здесь пример содержит более 180000 слов.
WordCount[textSpanish]Подсчёты частоты употребления каждого определённого слова представлены в качестве ассоциации от WordCounts. Результат отсортирован по убыванию.
association = WordCounts[textSpanish];Take[association, 10]Получите подсчёт частоты употребления 1000 наиболее распространённых слов.
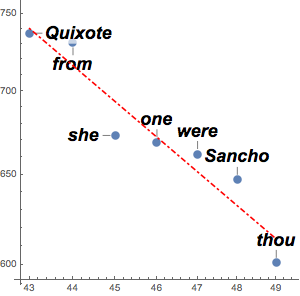
counts = Take[Values@association, 1000];Для нахождения приблизительных подсчётов с помощью степенного закона используйте логарифмы в линейной согласованности. Закон Ципфа утверждает, что экспонента должна быть приблизительно равна 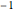 , а результат должен быть близким этому значению.
, а результат должен быть близким этому значению.
f[x_] = Fit[Log[Transpose[{Range[1000], counts}]], {1, x}, x]Визуализируйте согласованность с фактическими данными.

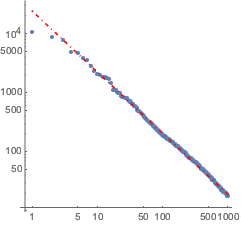
Закон Ципфа имеет силу в любом языке, поэтому данные вычисления возможны и с англоязычной версией "Дон Кихота".
textEnglish = ExampleData[{"Text", "DonQuixoteIEnglish"}];associationEnglish = WordCounts[textEnglish];
countsEnglish = Take[Values@associationEnglish, 1000];Take[associationEnglish, 10]И снова найденная экспонента приближена к 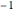 .
.
Fit[Log[Transpose[{Range[1000], countsEnglish}]], {1, x}, x]