大きなコーパスから文構造を集約する
Wolfram言語を使うと,大きいデータ集合が簡単に分析できる. この例では,ExtendedEntityClassを使って,Webサイトenglish.stackexchange.comへの投稿から100万を超える文の文法構造を抽出して調べる.
english.stackexchange.comから作ったEntityStoreをインポートする.
EntityValueで使うためにストアを登録する.
"single-word-requests"タグで分類された投稿について,最も頻繁に引用された,あるいは斜体・太字・リンクにされた単語を求め,結果のワードクラウドを作る.
投稿に使われた文構造を調べることで,このサイトをより広範囲に調べることができる.単文を抽出する特性を使用して,投稿の実体タイプを拡張することから始める.
新たな特性を使って投稿から100万を超える文を抽出する.
各文を空白文字または句読点で分割することで単語を求める.
ある論文によると,書かれた文1文当りの単語数は対数正規分布に従うと推測される.FindDistributionParametersを使ってコーパス内の各文の単語分布についてのフィッティングパラメータを求め,比較のためにそれらをプロットする.
個々の単語の出現頻度を求める.
DeleteStopwordsを使ってデータ集合をきれいにする.
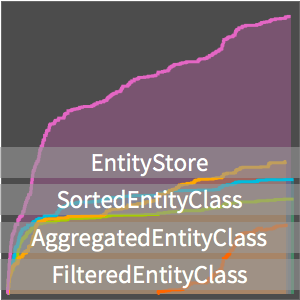
きれいになった単語数を両対数プロットで可視化する.
50個の単語に焦点を当て,Calloutを使って個々の単語を見る.
TextStructureでコーパスのすべての文を分析し,終了時に結果をファイルに追加する.このプロセスには非常に長い時間がかかり,評価が数日に及ぶこともあるので注意のこと.
ファイルからデータを読み込む.
特定の例を見る.
文の中心構造を抽出する関数を構築する.
すべての文の中心構造を抽出する.
データ中の文法単位すべてとそれぞれの出現頻度を求める.
連続した単位のペアごとに遷移数を求める.
以下は,名詞と前置詞の遷移数である.
MatrixPlotを使って各遷移の出現頻度を可視化する.
文を構造でグループ化する.
最も一般的な文構造をプロットで可視化する.
いくつかの興味深い構造について例文を見る.
1つの文法単位の挿入によって2つの構造が親子関係を共有する場合にその2つを接続することで,最もよく使われるいくつかの文構造のネットワークを作る.