큰 코퍼스에서 문장 구조 통합하기
Wolfram 언어를 사용하면 큰 데이터 세트를 쉽게 분석할 수 있습니다. 이 예는 ExtendedEntityClass를 사용하여 웹 사이트 english.stackexchange.com의 게시물에서 백만 개 이상의 문장의 문법 구조를 추출하여 조사합니다.
english.stackexchange.com에서 만든 EntityStore를 가져옵니다.
EntityValue에서 사용하기 위해 저장소를 등록합니다.
"single-word-requests" 태그로 분류된 게시물에 대해 가장 일반적인 인용, 또는 기울임 꼴, 글씨 굵기, 링크된 단어를 구하고, 결과의 워드 클라우드를 만듭니다.
게시물에 사용된 문장 구조를 조사함으로써 이 사이트를 더 광범위하게 조사할 수 있습니다. 간단한 문장을 추출하기 위해 특성을 사용하여 게시물의 실체 유형을 확장하는 것부터 시작합니다.
새로운 특성을 사용하여 게시물에서 백 만개 이상의 문장을 추출합니다.
각 문장을 공백 또는 문장 부호로 분할하여 단어를 찾습니다.
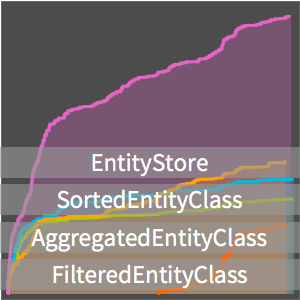
한 논문에 따르면, 논문의 한 문장 당 단어수는 로그 정규 분포를 따른다고 추측됩니다. FindDistributionParameters를 사용하여 코퍼스의 각 문장의 단어 분포에 대한 적합한 매개 변수를 구하고 비교를 위해 이것을 플롯합니다.
개별 단어의 출현 빈도를 구합니다.
DeleteStopwords를 사용하여 데이터 집합을 정리합니다.
정리된 단어 수를 두 로그 플롯으로 시각화합니다.
탑 50 개 단어에 초점을 맞추어 Callout을 사용하여 개별 단어를 알아봅니다.
TextStructure로 코퍼스의 모든 문장을 분석하고, 종료 시 결과를 파일에 추가합니다. 이 과정은 매우 긴 시간이 소요되며 평가가 며칠 동안 지속될 수도 있으므로 유의 해야합니다.
파일에서 데이터를 읽어 들입니다.
특정 예를 알아봅니다.
문장의 중심 구조를 추출하는 함수를 작성합니다.
모든 문장의 중심 구조를 추출합니다.
데이터에서 모든 문법 단위와 각각의 출현 빈도를 구합니다.
연속적인 단위의 쌍에 대해 전환 수를 구합니다.
다음은 명사와 전치사의 전이 개수입니다.
MatrixPlot을 사용하여 각 전환의 출현 빈도를 시각화합니다.
문장을 구조로 그룹화합니다.
가장 일반적인 문장 구조를 플롯에서 시각화합니다.
몇 가지 흥미로운 구조에 대한 예문을 알아봅니다.
하나의 문법 단위를 삽입해 두 개의 구조가 부모-자식 관계를 공유하는 경우에 이 두 가지를 연결하여 가장 많이 사용되는 여러 문장 구조의 네트워크를 만듭니다.