音声を認識する
自動音声認識 (Automatic speech recognition, ASR) は音声テキスト化 (speech-to-text, STT) としても知られるもので,話された言葉の録音を自動的に認識してテキストに変換するプロセスである.音声認識は,大規模な自動文字起こしシステム,バーチャルアシスタントとホームアシスタント,音声対応制御システム,口述システム,自動電話システム等でよく使われている.
バージョン12では,自動音声認識を行うSpeechRecognizeが導入された.
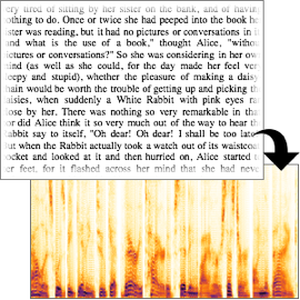
次は,Web上にあった音声信号である.
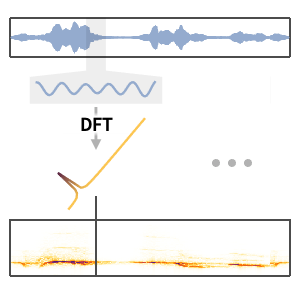
この信号のスペクトログラムを可視化する.
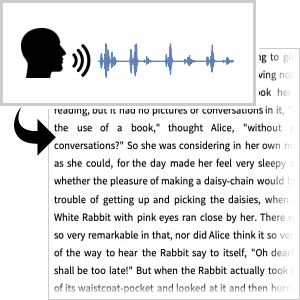
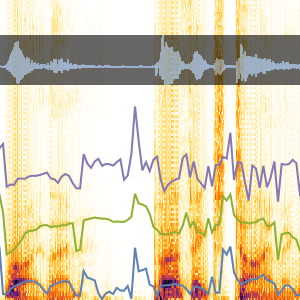
以下は,この信号の音声認識の結果である.音声認識のプロセスは,ニューラルネットワークを使って信号の生の文字起こしを計算し,次にスペルチェック等の目的で文字起こししたものを言語モデルを介して送ることである.