Verlinkte Daten von einer Webseite abfragen
Webseiten reagieren in der Regel mit "menschenlesbaren" Inhalten, wenn ein Browser (bedient durch einen "Menschen") eine Anfrage stellt. Um die Daten für die weitere Verarbeitung zu extrahieren, kann man stattdessen "maschinenlesbare" Daten anfordern.
Version 12 bietet Unterstützung für verschiedene RDF-Import und Export-Formate, wie beispielsweise "JSONLD" (ein Format, das auf "JSON" basiert, wobei "LD" auf "Linked Data" hinweist). Man kann verknüpfte Daten anfordern, indem man in einer HTTPRequest-Anfrage einen entsprechenden "accept"-Header angibt.
Dieses Beispiel importiert Daten zu den Titeln auf einem Album des berühmten Tango-Orchesterleiters Francisco Canaro von MusicBrainz.
Navigieren Sie zunächst zu einem Album Ihrer Wahl, z.B. über das Suchfeld und das Anklicken von Links in Ihrem Browser. Wenn Sie ein interessantes Album gefunden haben, kopieren Sie die URL und speichern Sie sie in einer Variablen.
So würde die Website in einem Browser aussehen.
Um verknüpfte Daten abzufragen, erstellen Sie eine HTTPRequest, die den JSON-LD Medientyp in ihrem "Accept"-Header festlegt.
Führen Sie den Auftrag aus und importieren Sie die Antwort mit dem Importer "JSONLD".
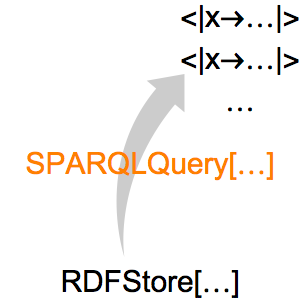
Das Ergebnis ist ein RDFStore-Objekt, das Informationen zu diesem Album enthält. Wenden Sie nun den SPARQLQuery-Operator an, um alle im Speicher verwendeten Eigenschaften abzurufen.
Schreiben Sie eine Abfrage, die für alle Titel die Tracknummer und den Namen abfragt.
Hier ist ein Beispiel-Titel.
Die Titelnummern sind Zeichenketten im Format disk.track. Extrahieren Sie den Titel und konvertieren Sie diese in einen "Integer", so dass Sie eine Reihenfolge nach Zahlen festlegen können.
Visualisieren Sie einen Datensatz, der nur die Titelnummer und den Titel anzeigt.