Webサイトからリンクトデータを要求する
Webサイトは,たいていの場合,ブラウザが「人間」に代って行う要求に対して「人間にとって可読」なコンテンツで応答するが,さらに処理する目的でデータを抽出するときは,「機械に可読」なデータを要求することができる.
バージョン12では,"JSONLD"("JSON"に基づく形式."LD"は"Linked Data"を示唆している)を含むRDF(Resource Description Framework,リソースディスクリプションフレームワーク)のImportとExportのための形式が数多くサポートされるようになった.リンクトデータは,HTTPRequestで適切な"accept"ヘッダを指定することでリクエストできる.
この例では,MusicBrainzから,有名なタンゴオーケストラの指揮者であるFrancisco Canaro(フランシスコ・カナロ)のアルバムのトラック情報をインポートする.
まず,検索ボックスを使ってブラウザのリンクをクリックする等して,使いたいアルバムを選択する.興味があるアルバムが見つかったら,そのURLをコピーして変数に格納する.
このWebサイトは,ブラウザでは次のように見える.
リンクトデータを要求するために,"accept"ヘッダでJSON-LD media typeを指定するHTTPRequestを作成する.
要求を実行し,"JSONLD"インポータを使って応答をインポートする.
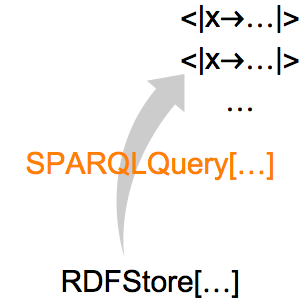
結果はこのアルバムに関連する情報を含むRDFStoreオブジェクトである.次に,SPARQLQuery演算子を適用してこのストアで使われているすべての特性を取り出す.
すべてのトラックについてトラック番号と曲名を要求するクエリを書く.
次はサンプルトラックである.
トラック番号は「ディスク.トラック」の形式の文字列である.数値的に"number"がソートできるように,「トラック」を抽出して"Integer"に変換する.
トラック番号と曲名だけを示すDatasetを表示する.