Analysez des données Wikipédia
Cet exemple effectue une analyse de données sur le dump complet du Wikipédia italien, qui, bien que moins volumineux que le Wikipédia anglais, occupe encore plus de 13 gigaoctets de données non compressées.
La fondation Wikimédia offre des dumps pour les bases de données de Wikipédia qui sont téléchargeables gratuitement en suivant les instructions ici.
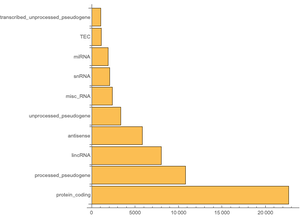
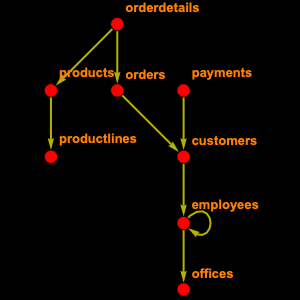
La base de données Wikipédia contient 56 tableaux. Vous n'aurez pas besoin de tous les tableaux, vous pouvez donc inspecter sélectivement ceux dont vous aurez besoin. À savoir, "page" qui contient les informations relatives à la page telles que le titre et la longueur, "revision" qui possède une entrée pour chaque version de la page et "text" qui contient le texte complet de l'article.
À partir de là, vous pouvez créer et enregistrer un objet EntityStore.
Découvrez le nombre de pages qu'il y a.
C'est plus élevé que le nombre cité sur la page principale. En fait, les pages de Wikipédia sont divisées en espaces de noms : 0 désignent les articles, 2 les pages utilisateurs, 4 les pages de discussion, et ainsi de suite. Donc, si vous limitez à des articles, vous obtenez ce qui suit.
Vous pouvez calculer la longueur moyenne d'un article de Wikipédia.
Ou vous pouvez calculer les 10 plus gros articles.
Il est intéressant de noter que la plus grande page correspond à l'histoire d'une petite région d'Italie.
Il est également utile de relier un article à son texte. Malheureusement ce n'est pas très facile parce que l'un des principes des wikis est de conserver la trace de toutes les révisions. Pour cela, il faut passer par le type d'entité "revision" pour y accéder.
Vous pouvez maintenant l'utiliser pour trouver le texte d'une page particulière.
Et lisez-le comme une chaîne de caractères.
Ou visualisez-le comme un nuage de mots.