Wikipediaデータを解析する
この例では,イタリア語のWikipediaの完全なダンプについてデータ解析を行う.イタリア語のWikipediaは,英語のものほど大きくはないが,それでも13ギガバイトを超える非圧縮のテキストを含む.
Wikimedia Foundationは,Wikipediaのデータベースダンプを提供する.これはここに記載される指示に従って無料でダウンロードできる.
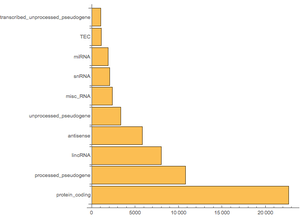
Wikipediaデータベース全体には,56個の表が含まれる.そのすべてが必要ではないので,使用するかもしれないものを調べて選ぶ.すなわち,タイトルや長さ等のページに関係する情報を含む"page",ページのすべてのバージョンについての項目を含む"revision",記事のテキスト全体を含む"text"が必要である.
ここから,EntityStoreオブジェクトを構築して登録することができる.
何ページになるかを調べる.
この数は,メインページに記載されている数よりも少し多い.これはWikipediaページが,0は記事,2はユーザページ,4はトークページ等,名前空間に分割されているからである.このため,記事だけに限定すると,以下の数が得られる.
Wikipedia記事の平均的な長さを計算する.
最長の記事10個を得る.
興味深いことに,最も大きなWikipediaページは,イタリアの小さな地域の歴史についてのページである.
もう一つの便利なこととして,記事をそのテキストに関連付けることがあるが,これは残念ながらあまりたやすいことではない.Wikipediaの原則の一つに,テキストのそれまでの改訂版をすべて記録しておくということがあるからである.
これで特定ページのテキストを見付けることができる.
これを文字列として読む.
あるいはワードクラウドとして可視化する.