字符串分解
查看基因的核甘酸中的密码子(三个连续核甘酸组)的相关频率.
获取人类基因 "SCNN1A" 的 DNA 序列.
In[1]:=
dnasequence = GenomeData["SCNN1A", "FullSequence"];用 StringPartition 构建密码子的相应列表.
In[2]:=
codons = StringPartition[dnasequence, 3];In[3]:=
Take[codons, 10]Out[3]=
计算在该基因中每个密码子的相对频率.
In[4]:=
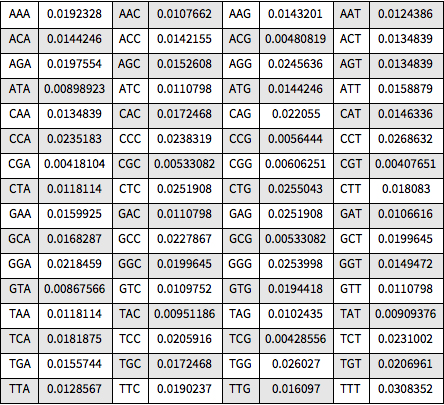
frequencies = N[Counts[codons]/Length[codons]];由 A、C、G、T 核甘酸构成 64 个可能的密码子,并都在所选基因中出现.
In[5]:=
frequencies // LengthOut[5]=
找出频率最高的三个密码子.
In[6]:=
TakeLargest[frequencies, 3]Out[6]=
找出频率最低的三个密码子.
In[7]:=
TakeSmallest[frequencies, 3]Out[7]=
在 Grid 中可视化所有相对频率.
显示完整的 Wolfram 语言输入

Out[8]=