对口述数字进行分类
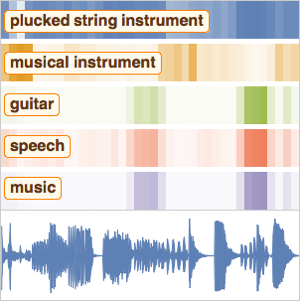
Wolfram 语言中的神经网络框架为 Audio 对象提供了功能强大且易于使用的网络训练工具。下面的例子训练网络对口述数字进行分类。
从 Wolfram Data Repository 获取 Spoken Digit Commands 数据集。
数据集由 0 到 9 数字的录音组成。实际上就是 MNIST 数字数据集的音频版本。
可以从决定如何将录音转换为神经网络可以使用的内容开始。我们使用了 "AudioMFCC" 网络编码器,其中信号被划分成相互重叠的分区,并且对每个分区进行一些处理以缩减大小,同时保留有助于理解信号的重要信息。
该网络将以 GatedRecurrentLayers 中一个简单的 NetChain 为基础。由于进行的是单个分类,因此循环层后面接的是 SequenceLastLayer 和线性分类器。
对网络进行训练,让 NetTrain 处理所有超参数。
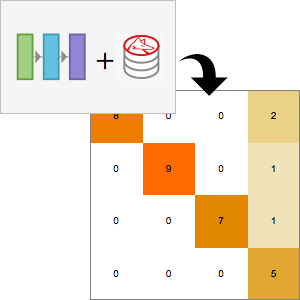
用 NetMeasurements 计算网络的性能。
删除最后的分类层,即可获得音频信号特征提取器。
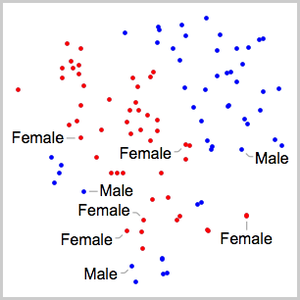
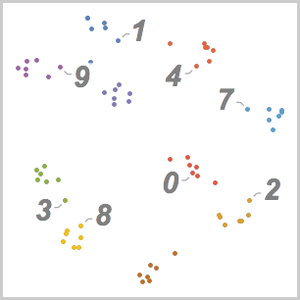
用 FeatureSpacePlot 可视化嵌入到由你训练的网络定义的特征空间中的测试数据集。
显示完整的 Wolfram 语言输入