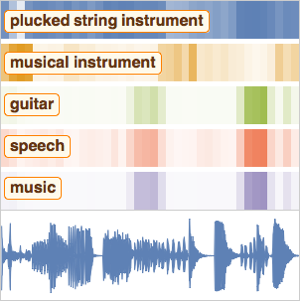
音読される数字を分類する
Wolfram言語におけるニューラルネットのフレームワークは,Audioオブジェクトのための強力で使いやすいネットワークの訓練ツールを可能にする.この例では,音読された数字を分類するネットを訓練する.
Wolfram Data RepositoryからSpoken Digit Commandsデータ集合を取り出す.
このデータ集合は,0から9までの数字の音読の録音でできている.MNISTデータ集合の音声版のようなものである.
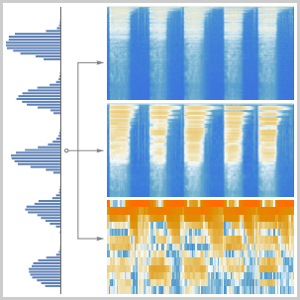
録音を,ニューラルネットワークで使えるものに変換する方法を決めるところから始める."AudioMFCC"ネットエンコーダを使う.これは,信号を重複する部分に分割し,信号の理解に重要な情報を保持したままで,次元を削減するために各部分に何らかの処理が適用される.
このネットワークは,GatedRecurrentLayerの簡単なNetChainに基づいている.単独の分類にしか関心がないので,回帰層の後にSequenceLastLayerと線形分類子が続く.
NetTrainにハイパーパラメータすべてを任せてネットを訓練することができる.
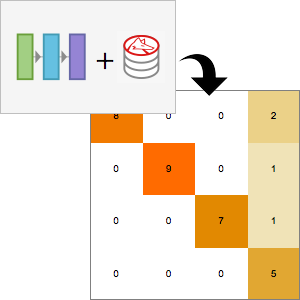
NetMeasurementsを使ってネットの性能を計算する.
最後の分類層を削除することによって,音声信号に対する特徴抽出器を得ることができる.
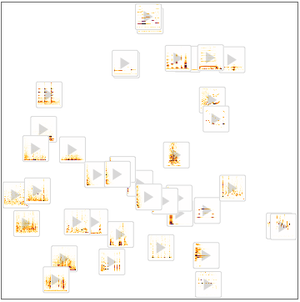
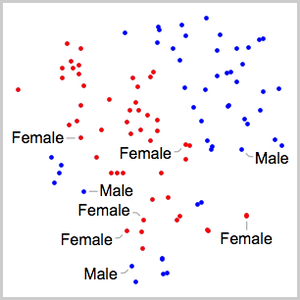
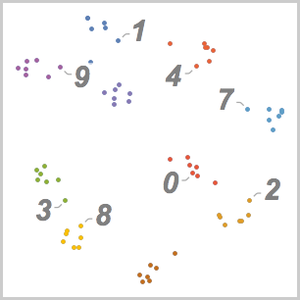
訓練したネットによって定義される特徴空間に埋め込まれた検証データ集合をFeatureSpacePlotを使って可視化する.
完全なWolfram言語入力を表示する