읽혀지는 숫자 분류하기
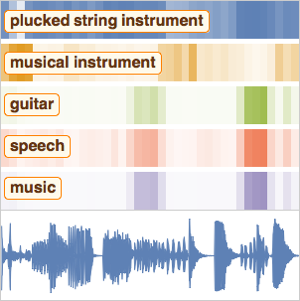
Wolfram 언어의 신경망 프레임워크는 Audio 객체를 위한 강력하고 사용하기 쉬운 네트워크의 훈련 도구를 가능하게 합니다. 이 예는 읽혀지는 숫자를 분류하는 네트워크를 훈련합니다.
Wolfram Data Repository에서 Spoken Digit Commands 데이터 집합을 가져옵니다.
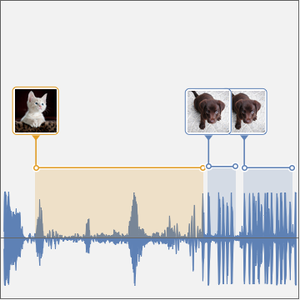
이 데이터 집합은 0에서 9까지의 숫자 읽기를 녹음할 수 있습니다. 기본적으로 MNIST 데이터 집합의 음성 버전과 같은 것입니다.
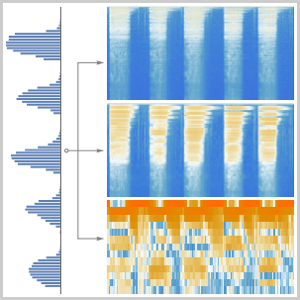
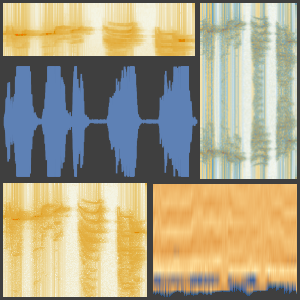
녹음을 신경망에서 사용할 수 있는 것으로 변환하는 방법을 결정하는 것부터 시작합니다. "AudioMFCC" 넷 인코더를 사용합니다. 이것은 신호를 중복하는 부분으로 분할하여 신호의 이해에 중요한 정보를 유지한 채로 차원을 줄이기 위해 각 부분에 어떤 처리가 적용됩니다.
이 네트워크는 GatedRecurrentLayer의 간단한 NetChain에 근거하고 있습니다. 단독 분류에만 관심이 있기 때문에 회귀층 후에 SequenceLastLayer와 선형 분류가 이어집니다.
NetTrain에 초매개변수 모두를 맡기고 넷을 훈련할 수 있습니다.
NetMeasurements를 사용하여 네트워크의 성능을 계산합니다.
마지막 분류층을 제거함으로써 음성 신호에 대한 특징 추출기를 얻을 수 있습니다.
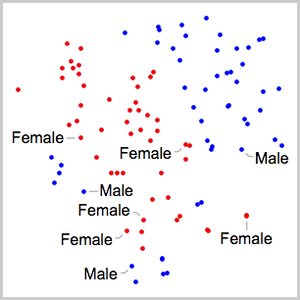
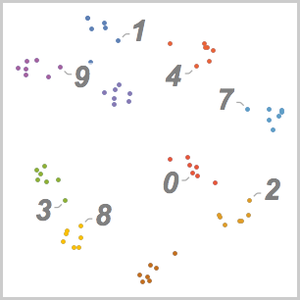
훈련한 넷에 의해 정의되는 특징 공간에 포함된 검증 데이터 집합을 FeatureSpacePlot을 사용하여 시각화합니다.
전체 Wolfram 언어 입력 표시하기