Ejemplos relacionados
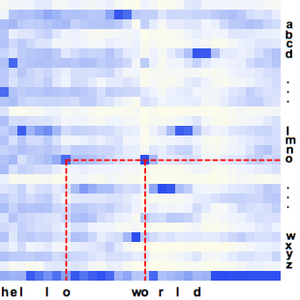
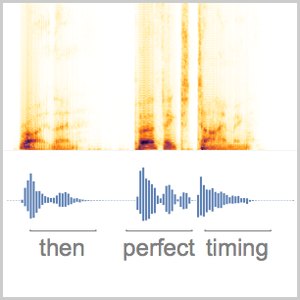

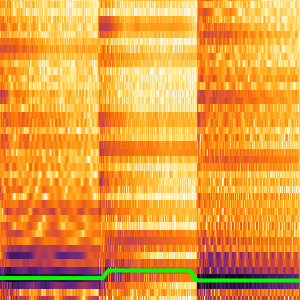
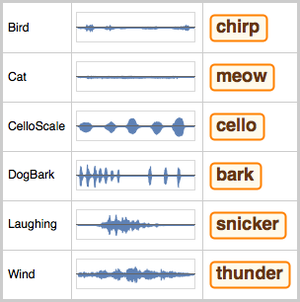

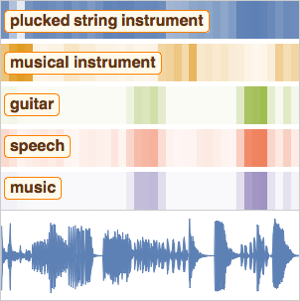


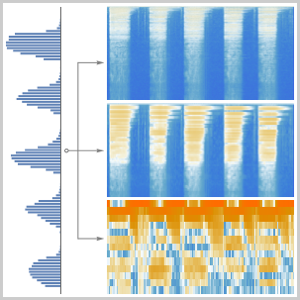
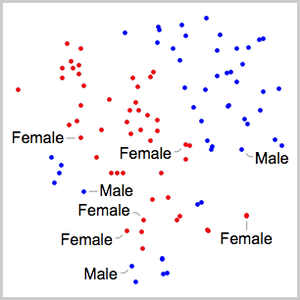
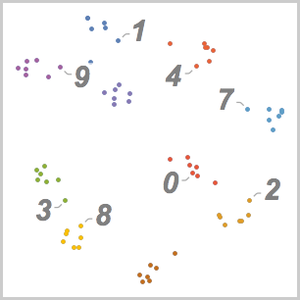

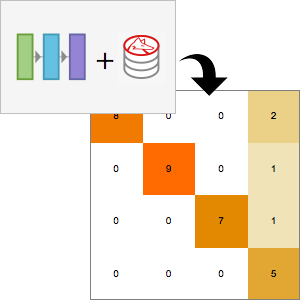
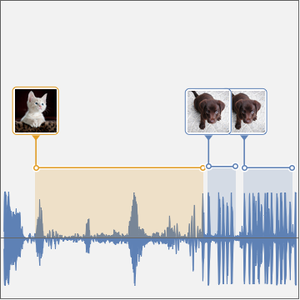


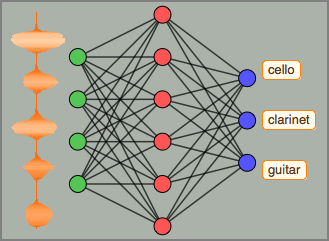
El procesamiento y análisis de audio de la versión 12 proporciona funciones incorporadas de alto nivel para la identificación de audio, el reconocimiento de voz y mucho más. Una integración eficiente y ajustada con el aprendizaje automático y el marco de redes neuronales, así como acceso fácil a un número creciente de avanzados modelos preentrenados, disponibles por medio del repositorio de redes neuronales de Wolfram, permite la creación de prototipos y desarrollo fácil de algoritmos. Todas estas capacidades a partir de un sistema rico y productivo para aplicar soluciones de aprendizaje automático de alto nivel y precisas a una amplia gama de campos, tales como voz y música.