Clasificación de dígitos hablados
El marco de redes neuronales de Wolfram Language permite herramientas de entrenamiento potentes y amistosas para el usuario para objetos de Audio. Este ejemplo entrena una red para clasificar dígitos hablados.
Recupere los conjuntos de datos de Spoken Digit Commands del Repositorio de datos Wolfram.
El conjunto de datos está compuesto de grabaciones de dígitos del 0 al 9. Es esencialmente el equivalente de audio del conjunto de dígitos MNIST.
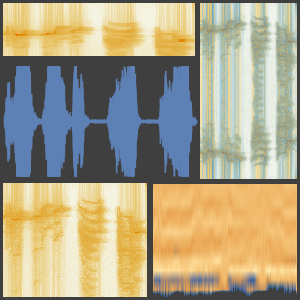
Usted puede comenzar decidiendo cómo una grabación será transformada en algo que una red neuronal pueda usar. El codificador de red "AudioMFCC" es usado, donde la señal se divide en partes superpuestas y algunos procesos son aplicados en cada una para reducir la dimensión en tanto preserva información que es importante para comprender la señal.
La red estará basada en una NetChain sencilla de GatedRecurrentLayers. Dado que usted está interesado en una sola clasificación, las capas recurrentes son seguidas por una SequenceLastLayer y un clasificador lineal.
Puede entrenar la red, dejando que NetTrain se ocupe de todos los hiperparámetros.
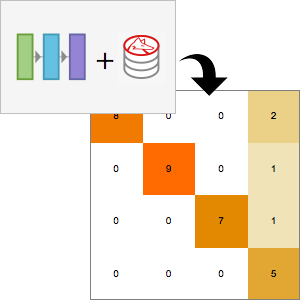
Calcule el rendimiento de la red usando NetMeasurements.
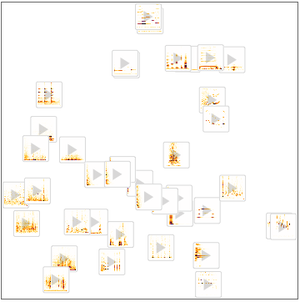
Al remover las últimas capas de clasificación, uested podrá obtener un extractor de atributos para señales.
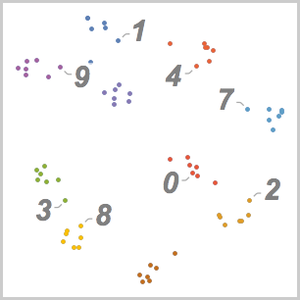
Use FeatureSpacePlot para visualizar el conjunto de datos de prueba incrustado en un espacio de atributos definido por la red que usted entrenó.