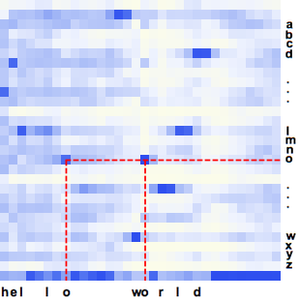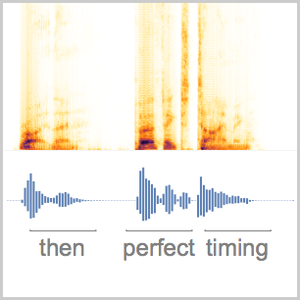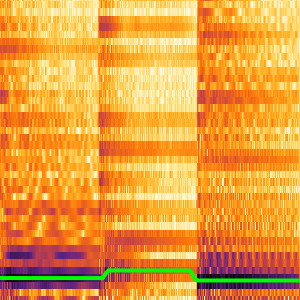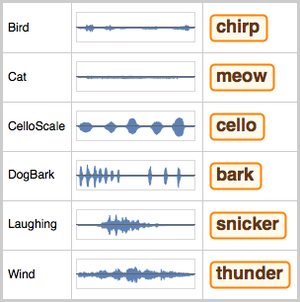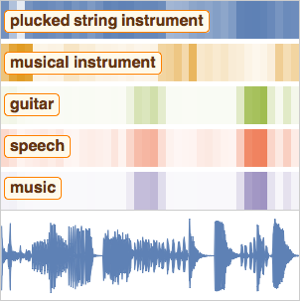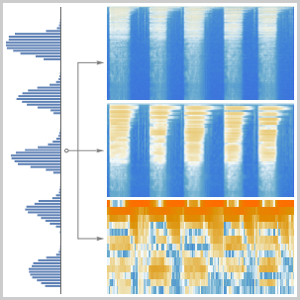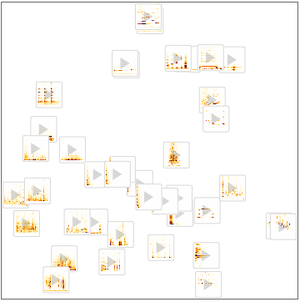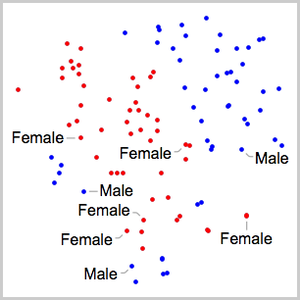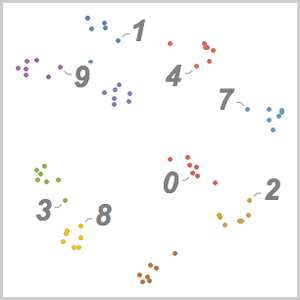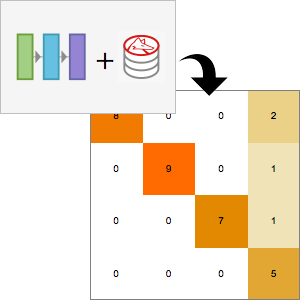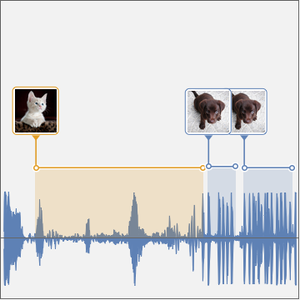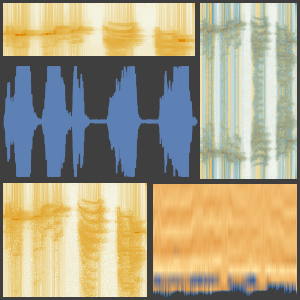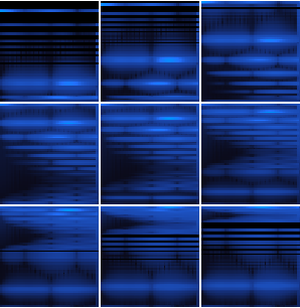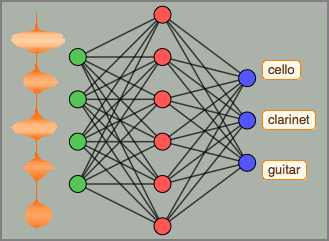
- Extraction intégrée des caractéristiques et représentation graphique de l'espace de caractéristiques. »
- Réseaux neuronaux entraînés et non entraînés immédiatement accessibles. »
- De nouveaux encodeurs efficaces pour les réseaux audio. »
- Prise en charge des réseaux récurrents. »
- Prise en charge de l'entraînement et de l'évaluation des GPU. »
Exemples connexes