训练声音事件检测网络
在某些情况下,想要训练网络确定录音中的声音事件,但只有 "weakly labeled" 的数据,其中的标签只告诉我们某个事件是否出现在录音中,但不知道出现的位置。尽管数据为我们提供的信息有限,但通过对弱标记数据的训练,依旧可以很好地确定录音中出现的声音事件的位置。
从 Wolfram Data Repository 中获取 Audio Cats and Dogs 数据集。
该数据集含有猫和狗的声音的注释录音。
录音的时长在 1 到 18 秒之间。
可以将数据集调整为适合于训练神经网络的格式,并将其拆分为训练子集和测试子集。
查看训练数据的累积时长。
测试数据的累积时长。
用 "AudioMelSpectrogram" 编码器将音频信号馈入网络。由于数据量相对较小,可以通过数据增强提高训练的效率。
网络本身基于循环层 (GatedRecurrentLayer) 的叠加,AggregationLayer 在时间维度上汇聚结果。因而网络输出的是单个分类结果而不是序列。
开始训练。
提取训练好的网,用没有增强的编码器替换编码器。
在测试集上生成性能报告。
通过删除 AggregationLayer 并将 SoftmaxLayer 重新添加到网络中,获得一个返回一系列类别概率而不是单个分类结果的网络。
定义一个获取网络输出的函数,并返回 TimeSeries 关联,其中包含可能的标签的概率。
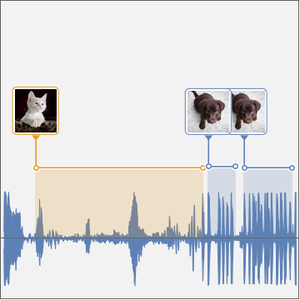
现在可以测试这个时间分辨网络。通过连接测试数据集中的猫和狗的声音样本构建信号。
显示完整的 Wolfram 语言输入
绘制由网络计算的概率的时间序列。
绘制对测试信号运用网络所得的结果。
定义一个函数来计算一个类的概率高于阈值的时间间隔,另一个函数来计算对应于那些间隔的矩形。
计算时间间隔。
在录音信号的波形上绘制时间间隔。
显示完整的 Wolfram 语言输入