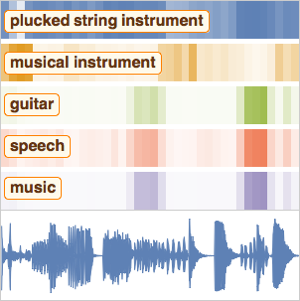
소리 이벤트 감지 넷 훈련하기
경우에 따라 녹음된 소리 이벤트의 위치를 찾을 수 있도록 네트워크를 훈련시키고 싶지만, 특정 이벤트가 녹음에 존재하는지 여부만을 기술하고 그 이벤트의 위치가 설명되지 않는 "부족한 라벨"을 가진 데이터에 대해서만 접근할 수 있는 때가 있습니다. 데이터의 제한에도 불구하고 부족한 라벨이 지정된 데이터의 훈련을 통해 소리 이벤트의 국소화에 좋은 결과를 얻는 것이 가능합니다.
Wolfram Data Repository에서 Audio Cats and Dogs 데이터 집합을 가져옵니다.
이 데이터 집합은 개와 고양이의 주석이 달린 녹음으로 이루어져 있습니다.
녹음 시간은 1초에서 18초까지 다양합니다.
데이터 집합을 조작하여 신경망의 훈련이 가능한 형식으로하여 훈련용과 검증용의 부분 집합으로 분할합니다.
훈련 데이터의 총 시간을 조사합니다.
검증 데이터를 합계합니다.
음성 신호 네트워크의 피드에는 "AudioMelSpectrogram" 인코더가 사용되고 있습니다. 데이터량이 비교적 작기 때문에, 데이터의 증강을 통해 훈련을 보다 효과적으로 할 수 있습니다.
넷 자체는 회귀층의 스택 (GatedRecurrentLayer)과 결과를 시간 차원에 충족시키는 AggregationLayer를 기반으로 한 것입니다. 이제 넷이 시퀀스 대신에 하나의 분류 결과를 출력할 수 있게 됩니다.
훈련을 시작합니다.
훈련된 넷을 추출하여 인코더를 확장하지 않은 것으로 대체합니다.
검증 집합의 성능 보고서를 작성합니다.
AggregationLayer를 제거하고 잘라낸 넷에 SoftmaxLayer를 다시 추가하면 단일 분류의 결과 대신에 등급 확률의 시퀀스를 반환하는 네트워크를 얻을 수 있습니다.
네트워크의 출력을 가지고 TimeSeries의 연상을 가능한 라벨의 확률과 함께 반환하는 함수를 정의합니다.
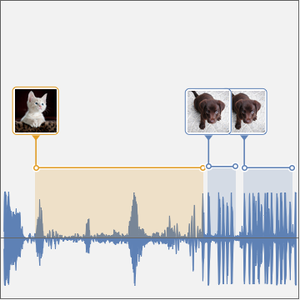
이제 시간 분해 넷을 검증할 수 있습니다. 검증용 데이터 집합에서 개와 고양이의 샘플을 연결해 신호를 구축합니다.
이 넷으로 계 한 확률의 시계열을 플롯합니다.
넷의 결과를 검증 신호에 플롯합니다.
클래스 확률이 임계치보다 높아지는 시간 간격을 계산하는 함수와 그 간격에 해당하는 사각형을 계산하는 함수를 정의합니다.
간격을 계산합니다.
간격을 녹음 파형 위에 플롯합니다.