Train a Self-Normalizing Neural Net
Historically, fully connected neural networks of more than a few layers have been extremely difficult to train. All deep nets were using weight sharing (such as convolution or recurrent layers). Also, neural nets had a hard time competing against traditional machine learning methods (Random Forest etc.) on non-perception tasks. Released in 2017, self-normalizing neural networks (SNN) is the first neural net architecture allowing deep fully-connected networks to be trained and also the first architecture competing with traditional methods on structured data (typically rows of classes and numbers). This example demonstrates how to create and train such a net.
SNNs are a very simple class of networks; they just use linear layers, an element-wise nonlinearity and a modified version of "Dropout" for regularization. Construct an SNN classifier of seven linear layers.
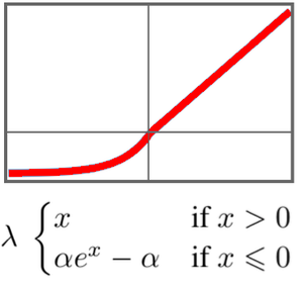
The key element in this network is its "SELU" (Scaled Exponential Linear Unit) nonlinearities. The "SELU" nonlinearity has the particularity of keeping the data standardized and avoids gradients getting too small or too large.
Train this network on the UCI Letter classification task.
Self-normalizing nets assume that the input data has a mean of 0 and variance of 1. Standardize the training and test data.
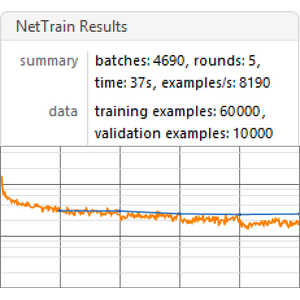
Train the net for 150 rounds, leaving 5% of the data for validation.
Use the network on a new example.
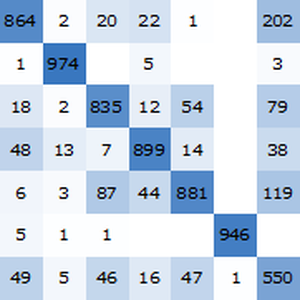
Obtain the accuracy of the trained net on the standardized test set.
The accuracy of the self-normalizing net (about 96.4%) compares well with classic machine learning methods.