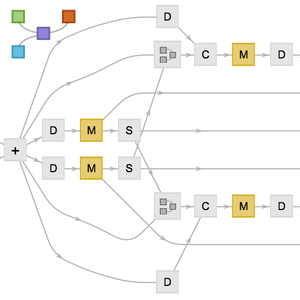
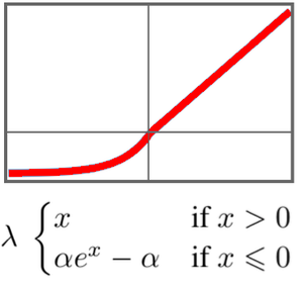
Train a Net on Multiple GPUs
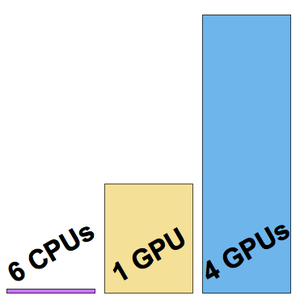
To reduce training time, a neural net can be trained on a GPU instead of a CPUs. The Wolfram Language now supports neural net training using multiple GPUs (from the same machine), allowing even faster training. The following example shows trainings on a 6-CPU and 4-NVIDIA Titan X GPU machine.
Load a subset of the CIFAR-10 training dataset.
Load the architecture of the "Wolfram ImageIdentify Net V1" from the Wolfram Neural Net Repository.
Preprocess the input data using the net NetEncoder to avoid CPU preprocessing bottleneck estimations of the net's training speed.
Remove the now unnecessary NetEncoder and replace the net head and the final NetDecoder so that they match the classes in the dataset.
Launch the training on the machine with a 6-core CPU:
This training was performed at a speed of about eight examples per second.
Launch the training on a single GPU (the fourth one, as it is not recommended to use the GPU in charge of the display).
This time, the training was performed at a speed of about 200 examples per second.
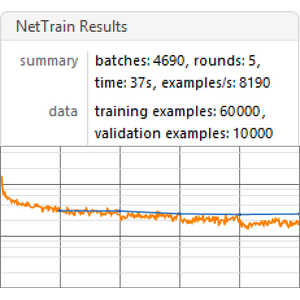
Now launch the training on all four GPUs.
The training speed is now about 500 examples per second.
Visualize the three training speeds measured.