训练音频分类器
下面的例子演示如何训练用于音频分类的简单神经网络,以及如何使用它来提取音频特征
从 ResourceData 获取 "Spoken Digit Commands" 数据集,包括不同的人对从 0 到 9 的数字的发音,以及它们的标签和发声者的 ID。
音频数据的初始编码比图像数据更复杂,更重要。有各种编码算法可用于音频数据,包括 "AudioMFCC",它可以产生用向量序列给出的信号的紧凑表示。
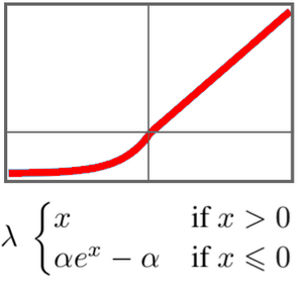
定义基于一组 GatedRecurrentLayer 的分类网络。可用 NetBidirectionalOperator 使网络层变成双向的,从两个方向读取序列并连接结果。用 SequenceLastLayer 提取循环层的最终状态。
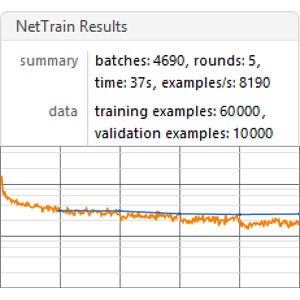
用 NetTrain 训练网络,并保留 5% 的数据进行验证。
在测试集的一个样例上运行最终的网络。
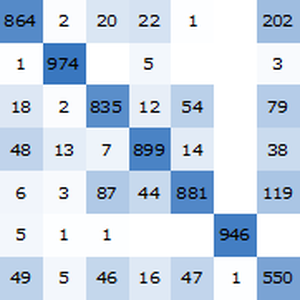
用 NetMeasurements 在测试集上计算准确性。
通过删除最后的分类层,可将该网络用作高级特征提取器。
可用该提取器通过少量数据快速训练新模型。下面的例子用 50 个训练样例通过 Classify 训练新的分类器。
获取分类器的性能信息。