在强化学习环境中训练智能体
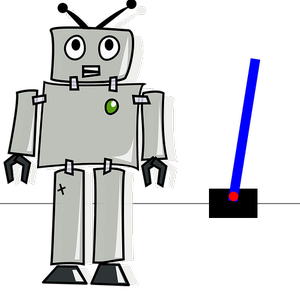
这个例子演示了如何训练一个简单的神经网络,通过使用 REINFORCE 方法 (Williams, 1992) 在 "Simulated Cart Pole" 环境中最大化奖励。cart pole 环境包括一个沿无摩擦的一维轨道移动的推车和一个通过铰链(又称倒立摆)固定到推车上的加重杆。推车有一定的初始速度,这样杆就会在没有干预的情况下倾倒。智能体的目的是尽可能长时间地保持杆子直立。这是通过学习在任何给定时间执行两个可能的动作(向左移动或向右移动)中的哪一个来完成的。
加载并用初始状态渲染环境。
定义一个简单的网络,该网络将学习选择向左还是向右移动推车的策略。
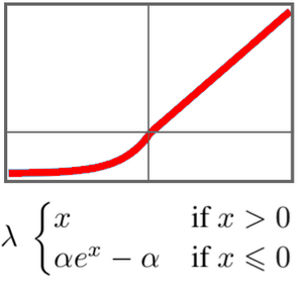
定义策略梯度学习的损失函数。
定义一个生成器函数,对网络的训练数据进行采样。
显示完整的 Wolfram 语言输入
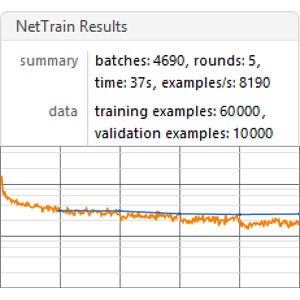
训练策略网络,测量平均折扣奖励。
用动画显示具有训练过的策略网络的环境(单击下面的图像观看动画)。注意杆一直保持直立。
与在环境中随机动作的智能体相比较(单击下面的图像观看动画)。