音声分類子を訓練する
この例では,単純なニューラルネットワークを音声分類のためにどのように訓練するか,またこれを使って音声特徴をどのように抽出するかを示す.
さまざまな話者による0から9までの数字の発音の録音と,そのラベルおよび話者IDからなる"Spoken Digit Commands"データ集合をResourceDataから入手する.
音声データの初期符号化は画像データのそれよりも,より複雑でより重要である.音声には,ベクトル列に基づいた信号の圧縮表現を作成する"AudioMFCC"を含むさまざまな符号化アルゴリズムが使用できる.
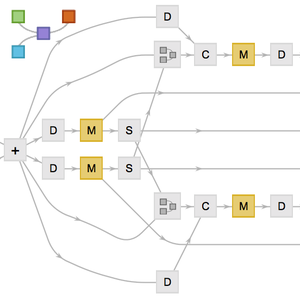
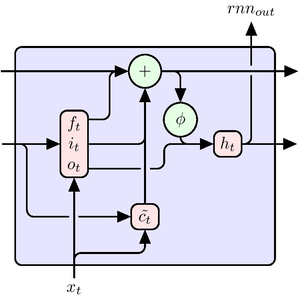
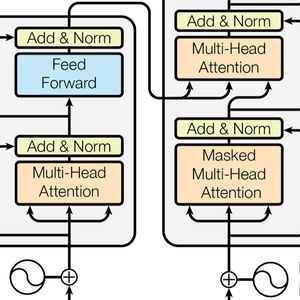
積み重ねたGatedRecurrentLayerに基づいて分類ネットワークを定義する.NetBidirectionalOperatorを使って層を双方向にし,シーケンスを両方向に読んで結果を繋ぎ合せることができる.回帰の最終状態はSequenceLastLayerで取り出すことができる.
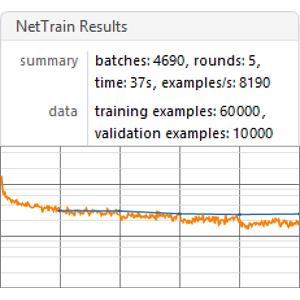
NetTrainを使ってネットを訓練する.データの5%は検証のために残しておく.
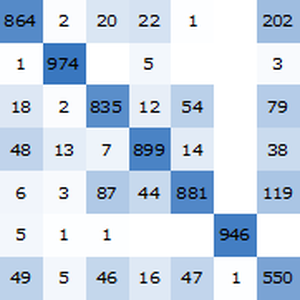
最終ネットを検証集合からの例で評価する.
NetMeasurementsを使って検証集合について確度を計算する.
このネットは,最後の分類層を削除すると,高レベルの特徴抽出器として使うことができる.
抽出器を使って新たなモデルを少量のデータで非常に素早く訓練することができる.例として,たった50個の訓練例しか使わずにClassifyで新たな分類子を訓練する.
この分類子の性能情報を入手する.