在多个 GPU 上训练网络
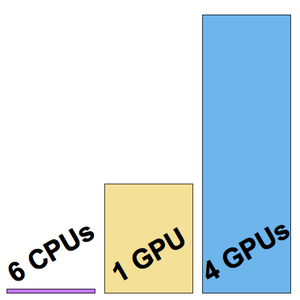
为了减少训练时间,可以在 GPU 上而不是 CPU 上训练神经网络。Wolfram 语言现在支持用多个 GPU (来自同一台机器)进行神经网络训练,以加快训练速度。下面的例子显示了在有 6 个 CPU 的机器上和在有 4 个 NVIDIA Titan X GPU 的机器上进行训练的情况。
加载 CIFAR-10 训练数据集的子集。
从 Wolfram Neural Net Repository 加载 "Wolfram ImageIdentify Net V1" 架构。
用 NetEncoder 对输入数据进行预处理,以避免 CPU 预处理对估计网络的训练速度造成瓶颈。
删除不再需要的 NetEncoder 并替换第一个网络和最终的 NetDecoder,以便与数据集中的类相匹配。
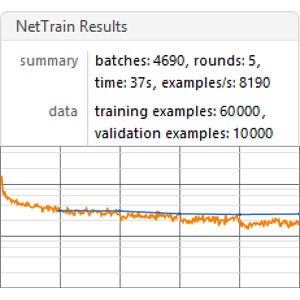
在有 6 核 CPU 的机器上开始训练:
训练以每秒约 8 个样例的速度进行。
在单个 GPU(第四个,不建议使用负责显示的 GPU )上开始训练。
这次,训练以每秒约 200 个样例的速度进行。
在四个 GPU 上开始训练。
现在训练速度是每秒约 500 个样例。
可视化测得的三个训练速度。