言語,アルファベット,文字体系の特徴を調べる
バージョン11では,言語,文字体系,アルファベットについての幅広い組込み知識が利用できる.
異なる言語において同じ文字体系(筆記形式)を使っていても,アルファベットの文字は異なるという場合がある.この例では,ラテン文字体系を使う言語における文字の数の大きな違いを調べる.
ラテン文字体系を使うアルファベットのリストを取り出す.
In[1]:=
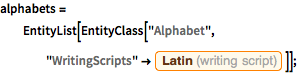
alphabets =
EntityList[
EntityClass["Alphabet",
"WritingScripts" -> Entity["WritingScript", "Latin::6tr5q"]]];In[2]:=
Length[alphabets]Out[2]=
131個のそのようなアルファベットが存在する.そのうちのほんの一部を表示する.
In[3]:=
RandomSample[alphabets, 15]Out[3]=

各アルファベットの文字のリストを保存する連想を構築する.
In[4]:=
letters =
EntityValue[alphabets, "CommonAlphabet", "EntityAssociation"];最も短いアルファベットは12文字のモホーク語である.
In[5]:=
letters[Entity["Alphabet", "Mohawk::p8wq4"]]Out[5]=
最も長いアルファベットは,46文字を含むスロバキア語である.
In[6]:=
letters[Entity["Alphabet", "Slovak::kj62d"]]Out[6]=
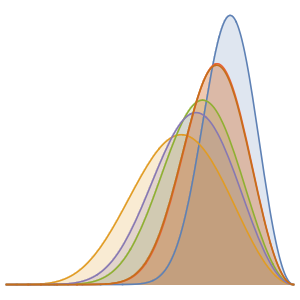
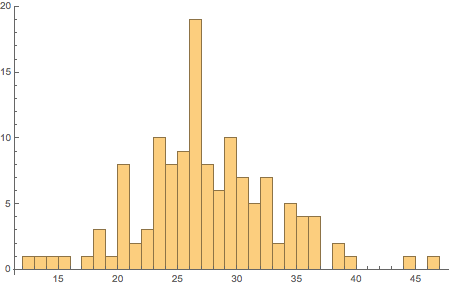
このヒストグラムは,最もよくある長さは,英語のように26文字であるが,26文字のアルファベットすべてに同じ文字が含まれているわけではないことを示している.
In[7]:=
Histogram[Length /@ letters, 30]Out[7]=
ある文字が含まれるアルファベットの数を数える.131個のラテン文字体系のアルファベットすべてに含まれるのは,a,i,nの3文字だけである.
In[8]:=
TakeLargest[Counts[Flatten[Values[letters]]], 10]Out[8]=
モホーク語はmの文字を含まない.そしてtの文字を含まないアルファベットは,ハワイ語だけである.
In[9]:=
letters[Entity["Alphabet", "Hawaiian::p38r5"]]Out[9]=