研究语言、字母和代码的特征
版本 11 提供了与语言、书写代码和字母相关的丰富内置知识接口.
不同的语言可能会共享同一书写代码(或书写系统),但仍使用不同字母的字符. 本例探讨了使用拉丁书写代码的语言中字符数目的较大变异性.
取使用拉丁书写代码的字母列表.
In[1]:=
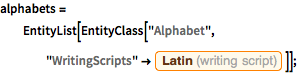
alphabets =
EntityList[
EntityClass["Alphabet",
"WritingScripts" -> Entity["WritingScript", "Latin::6tr5q"]]];In[2]:=
Length[alphabets]Out[2]=
共有 131 个这种字母表. 显示它们中的一小部分.
In[3]:=
RandomSample[alphabets, 15]Out[3]=

构建一个关联,存储每个字母表的字符列表.
In[4]:=
letters =
EntityValue[alphabets, "CommonAlphabet", "EntityAssociation"];最短的字母表是莫霍克语,有 12 个字母.
In[5]:=
letters[Entity["Alphabet", "Mohawk::p8wq4"]]Out[5]=
最长的字母表是斯洛伐克语,有46个字符.
In[6]:=
letters[Entity["Alphabet", "Slovak::kj62d"]]Out[6]=
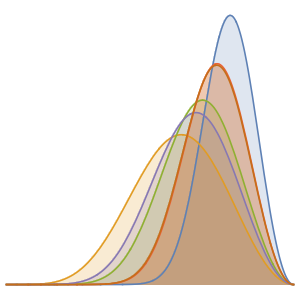
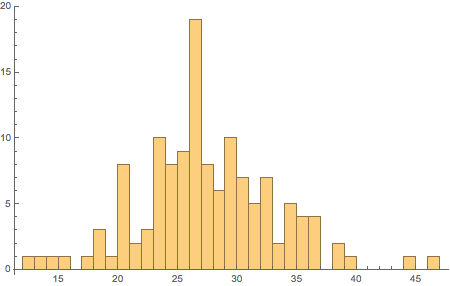
直方图显示最常见的长度是 23 个字母,比如英语,尽管并非所有的 26 字母表包含的都是相同的字母.
In[7]:=
Histogram[Length /@ letters, 30]Out[7]=
现在计算出现给定字母的字母表个数. 仅有三个字母存在于所有这 131 个拉丁字母表中, 它们是 a、i 和 n.
In[8]:=
TakeLargest[Counts[Flatten[Values[letters]]], 10]Out[8]=
莫霍克语不含有字母 m,夏威夷字母表是唯一不含有字母 t 的字母表.
In[9]:=
letters[Entity["Alphabet", "Hawaiian::p38r5"]]Out[9]=