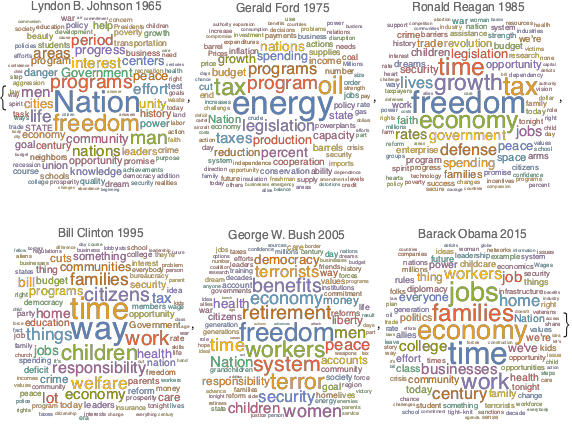
Частота употребления нарицательных существительных в речах
Используйте TextCases для получения подстрок для заданной формы, например, существительного или глагола, а также стран, электронных адресов и многого другого.
Получите набор данных о всех речах президентов США, произнесённых во время совместных заседаний Конгресса Соединённых Штатов.
In[1]:=
data = ResourceData["State of the Union Addresses"];Уменьшите размер данных, сохранив только имена президентов, год речей и их текст.
In[2]:=
reduceddata = data[All, {"President", "Year", "Text"}];Возьмите случайные речи с 10-летним промежутком.
In[3]:=
years = Range[1965, 2015, 10];
speeches = Select[reduceddata, MemberQ[years, #Year] &]Out[3]=

Используйте TextCases для определения существительных в каждой речи.
In[4]:=
nouns = TextCases[Normal@speeches[All, "Text"], "Noun"];Посчитайте наличие всех явственных существительных в каждой речи.
In[5]:=
freqnouns = Counts /@ nouns;Не принимайте в расчёт слова, которые имели частое употребление в большинстве годов.
In[6]:=
freqnouns =
KeyDrop[freqnouns, {"country", "people", "year", "years", "world"}];Сгенерируйте словарные облака, демонстрирующие частоту употребления существительных во времени.
код на языке Wolfram Language целиком

Out[7]=