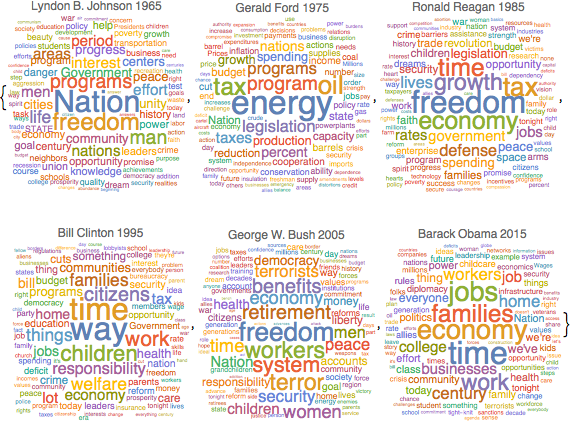
Frequency of Common Nouns in Speeches
Use TextCases to extract substrings of a given form, for instance nouns or verbs, as well as countries, email addresses, and many other things.
Retrieve a dataset of all speeches delivered by the US presidents during joint sessions of the United States Congress.
In[1]:=
data = ResourceData["State of the Union Addresses"];Reduce the size of the dataset by keeping only the president names, years of speeches, and texts of speeches.
In[2]:=
reduceddata = data[All, {"President", "Year", "Text"}];Take a sample of speeches at 10-year intervals.
In[3]:=
years = Range[1965, 2015, 10];
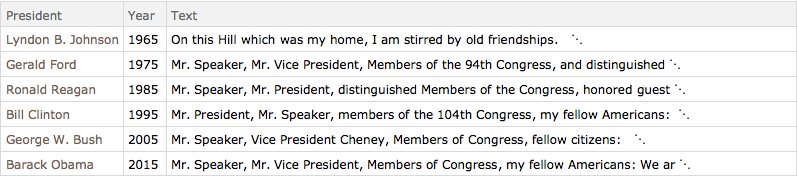
speeches = Select[reduceddata, MemberQ[years, #Year] &]Out[3]=
Use TextCases to identify the nouns in each speech.
In[4]:=
nouns = TextCases[Normal@speeches[All, "Text"], "Noun"];Count the occurrences of all distinct nouns in each speech.
In[5]:=
freqnouns = Counts /@ nouns;Ignore some words that are very common across most years.
In[6]:=
freqnouns =
KeyDrop[freqnouns, {"country", "people", "year", "years", "world"}];Generate word clouds showing the frequency of nouns over time.
show complete Wolfram Language input

Out[7]=