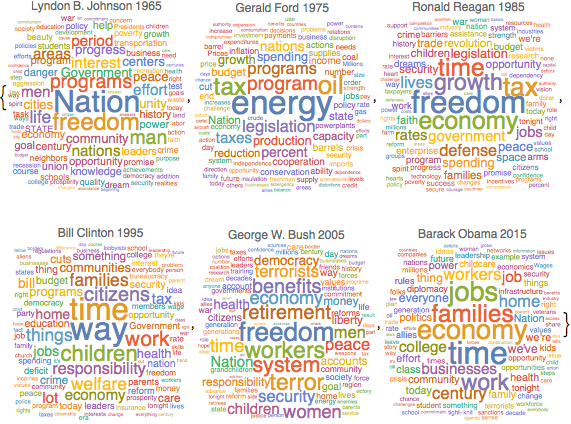
Frequência de substantivos comuns nos discursos
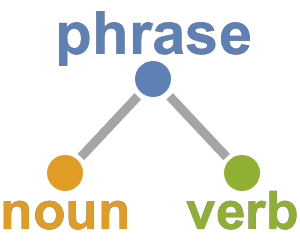
Use TextCases para extrair subcadeia de caracteres em um dado formato, por exemplo substantivos ou verbos, assim como países, endereços de e-mail, e muitas outras coisas.
Extraia um conjunto de dados de todos os discursos feitos pelo presidente dos Estado Unidos durante sessões conjuntas com o Congresso dos Estados Unidos.
data = ResourceData["State of the Union Addresses"];Reduza o tamanho do conjunto de dados matendo apenas os nomes dos presidentes, anos dos discursos, e o texto dos discursos.
reduceddata = data[All, {"President", "Year", "Text"}];Pegue uma amostra de discursos num intervalo de 10 anos.
years = Range[1965, 2015, 10];
speeches = Select[reduceddata, MemberQ[years, #Year] &]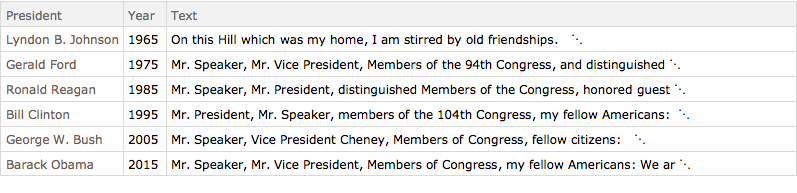
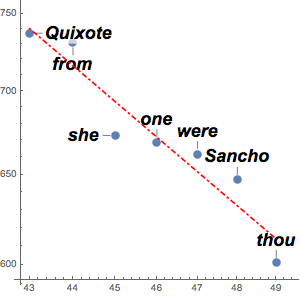
Use TextCases para identificar os substantivos em cada discurso.
nouns = TextCases[Normal@speeches[All, "Text"], "Noun"];Conte a ocorrência de todos os substantivos distintos em cada discurso.
freqnouns = Counts /@ nouns;Ignore algumas palavras que são muito comuns na maioria dos anos.
freqnouns =
KeyDrop[freqnouns, {"country", "people", "year", "years", "world"}];Crie uma nuvem de palavras mostrando a frequencia dos substantivos ao longo to tempo.