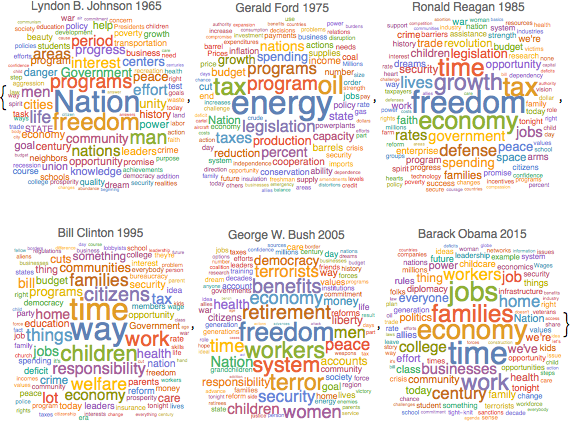
대화에 사용되는 보통 명사 빈도
TextCases를 사용하여 예를 들어 명사 혹은 동사, 그리고 국가, 이메일 주소, 등등 지정된 형식의 부분 문자열을 추출합니다.
미국 양원 합동 회의에서 대통령에 직접 연설한 모든 연설의 데이터 집합을 추출합니다.
In[1]:=
data = ResourceData["State of the Union Addresses"];대통령의 이름, 연설 연도, 연설 원고만을 남겨 데이터 집합의 크기를 줄입니다.
In[2]:=
reduceddata = data[All, {"President", "Year", "Text"}];연설 샘플을 10년 간격으로 추출합니다.
In[3]:=
years = Range[1965, 2015, 10];
speeches = Select[reduceddata, MemberQ[years, #Year] &]Out[3]=
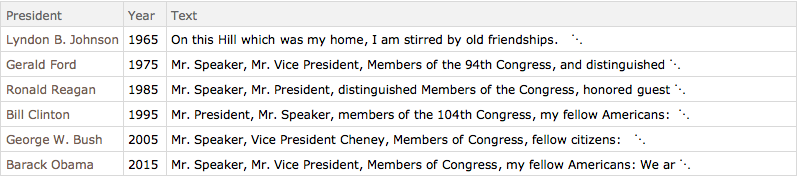
TextCases를 사용하여 각 연설에 포함된 명사를 특정합니다.
In[4]:=
nouns = TextCases[Normal@speeches[All, "Text"], "Noun"];각 연설에서 사용된 다른 명사와 다른 모든 단어를 셉니다.
In[5]:=
freqnouns = Counts /@ nouns;대부분의 해에 공통되는 단어를 무시합니다.
In[6]:=
freqnouns =
KeyDrop[freqnouns, {"country", "people", "year", "years", "world"}];시간의 흐름에 따른 명사 빈도를 나타내는 워드 클라우드를 생성합니다.
전체 Wolfram 언어 입력 표시하기

Out[7]=