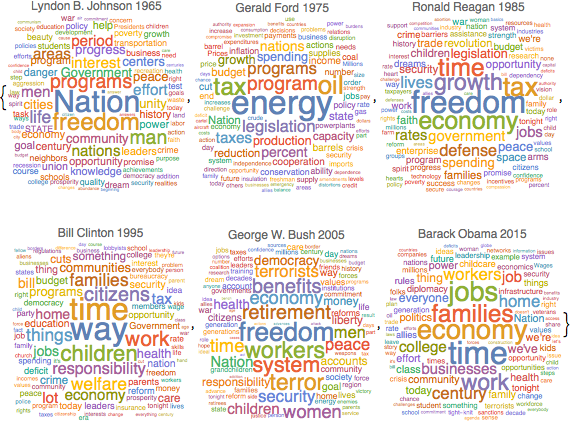
演讲中常用名词的频率
用 TextCases 提取给定格式的子字符串,例如,名词或动词,以及国家、电邮地址和其他内容.
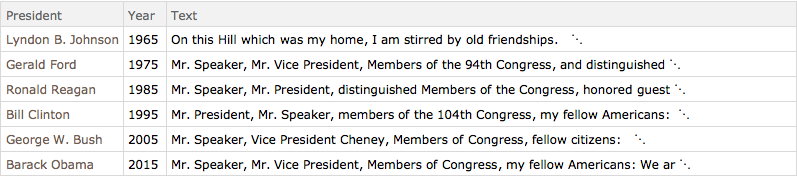
提取在美国国会上下两议院的联席会议间,美国总统发表的所有演讲的数据集.
In[1]:=
data = ResourceData["State of the Union Addresses"];通过仅保留总统姓名、演讲年份和演讲稿减小数据集的大小.
In[2]:=
reduceddata = data[All, {"President", "Year", "Text"}];每 10 年提取一个演讲样本.
In[3]:=
years = Range[1965, 2015, 10];
speeches = Select[reduceddata, MemberQ[years, #Year] &]Out[3]=
用 TextCases 识别每个演讲中的名词.
In[4]:=
nouns = TextCases[Normal@speeches[All, "Text"], "Noun"];计算每个演讲中出现的不同名词的个数.
In[5]:=
freqnouns = Counts /@ nouns;忽略在大多数年份中常见的单词.
In[6]:=
freqnouns =
KeyDrop[freqnouns, {"country", "people", "year", "years", "world"}];生成词云,显示名词词频随时间变化的情况.
显示完整的 Wolfram 语言输入

Out[7]=