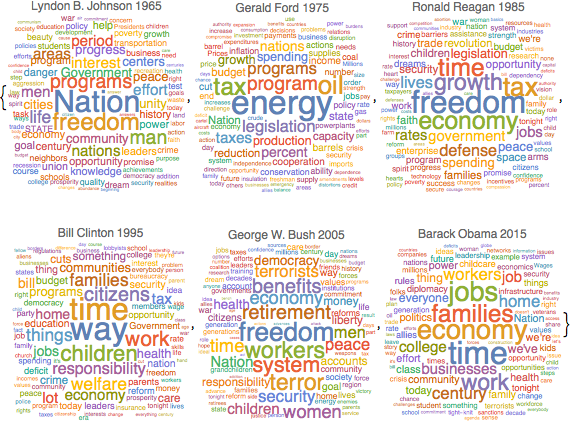
演説における普通名詞の頻度
TextCasesを使って,例えば名詞あるいは動詞,国,電子メールアドレス,その他の指定の形式の部分文字列を取り出す.
アメリカ合衆国の両院合同会議でのアメリカ大統領によるすべての演説のデータ集合を取り出す.
In[1]:=
data = ResourceData["State of the Union Addresses"];大統領名,演説の行われた年,演説原稿だけを残すことでデータ集合のサイズを小さくする.
In[2]:=
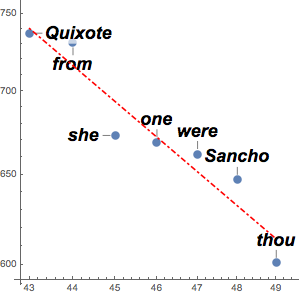
reduceddata = data[All, {"President", "Year", "Text"}];演説のサンプルを10年間隔で取り出す.
In[3]:=
years = Range[1965, 2015, 10];
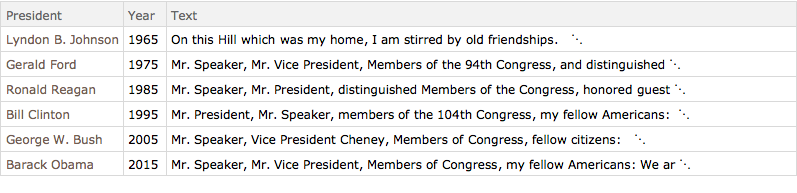
speeches = Select[reduceddata, MemberQ[years, #Year] &]Out[3]=
TextCasesを使って各演説に含まれる名詞を特定する.
In[4]:=
nouns = TextCases[Normal@speeches[All, "Text"], "Noun"];各演説で使われた他とは異なる単語すべての頻度を数える.
In[5]:=
freqnouns = Counts /@ nouns;ほとんどの年に共通している単語を無視する.
In[6]:=
freqnouns =
KeyDrop[freqnouns, {"country", "people", "year", "years", "world"}];時間の変化の中での名詞頻度を示すWordCloudsを生成する.
完全なWolfram言語入力を表示する

Out[7]=