Descomposición de cadenas de caracteres
Examine las frecuencias de codones (grupos de nucleótidos consecutivos) en la lista de nucleótidos de un gen.
Obtenga la secuencia de ADN de un gen humano "SCNN1A".
In[1]:=
dnasequence = GenomeData["SCNN1A", "FullSequence"];Use StringPartition para construir la correspondiente lista de codones.
In[2]:=
codons = StringPartition[dnasequence, 3];In[3]:=
Take[codons, 10]Out[3]=
Calcule la frecuencia relativa de cada codón en este gen.
In[4]:=
frequencies = N[Counts[codons]/Length[codons]];Existen 64 posibles codones formados a partir de los nucleótidos A, C, G, T, y aparecen en el gen seleccionado.
In[5]:=
frequencies // LengthOut[5]=
Encuentre los tres codones con las frecuencias más altas.
In[6]:=
TakeLargest[frequencies, 3]Out[6]=
Encuentre los tres codones con las frecuencias más bajas.
In[7]:=
TakeSmallest[frequencies, 3]Out[7]=
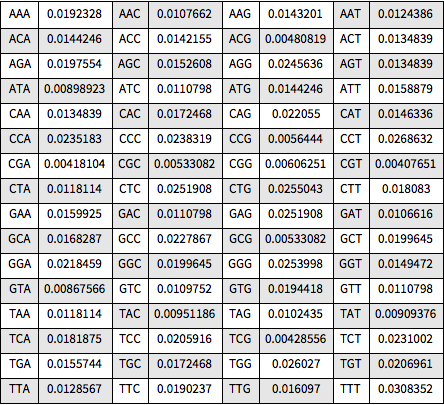
Visualice todas las frecuencias en un Grid.
muestre la entrada completa de Wolfram Language

Out[8]=