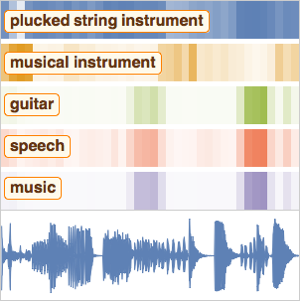
Classifique dígitos falados
A estrutura de rede neural na Wolfram Language traz ferramentas de treinamento de rede poderosas e fáceis de usar para objetos de Audio. Este exemplo treina uma rede para classificar dígitos falados.
Extraia o conjunto de dados Spoken Digit Commands do Wolfram Data Repository.
O conjunto de dados possui gravações dos dígitos de 0 a 9. É essencialmente um áudio equivalente ao conjunto de dados MNIST de dígitos.
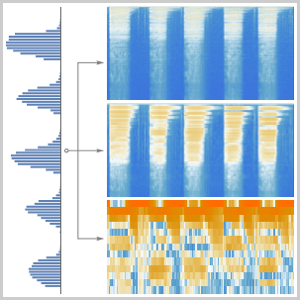
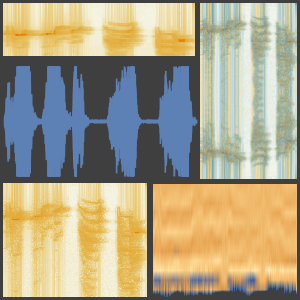
Você pode começar decidindo como uma gravação será transformada em algo que uma rede neural pode usar. O codificador de rede "AudioMFCC" é usado onde o sinal é dividido em partições sobrepostas e algum processamento é aplicado a cada uma das partições para reduzir a dimensão enquanto preserva a informação que é importante para entender o sinal.
A rede será baseada em uma NetChain simples de GatedRecurrentLayers. Como você está interessado em uma única classificação, as camadas recorrentes são seguidas por um SequenceLastLayer e um classificador linear.
Você pode treinar a rede, deixando que NetTrain se preocupe com todos os hiperparâmetros.
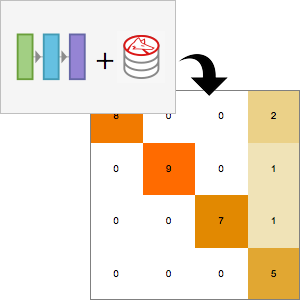
Calcule o desempenho da rede usando NetMeasurements.
Ao remover as últimas camadas de classificação, você pode obter um extrator de propriedades para sinais de áudio.
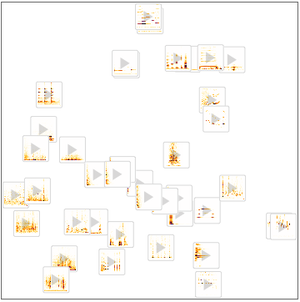
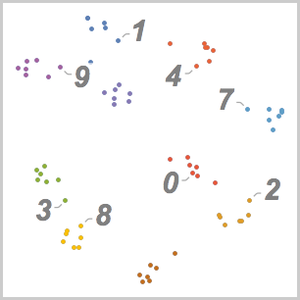
Use FeatureSpacePlot para visualizar o conjunto de dados de teste incorporado em um espaço de recurso definido pela rede que você treinou.