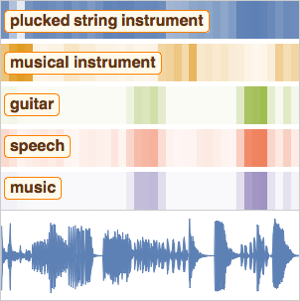
Reconocimiento de palabras claves en el habla
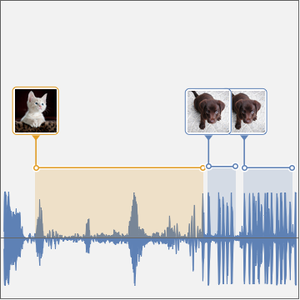
Además de una simple transcripción de voz, calcular la probabilidad de que recodificación contenga cualquiera de las palabras de un conjunto restringido proporciona cierta resistencia a los errores de ortografía que la red podría cometer. Aún más, puede ser muy útil localizar dónde se pronuncia una palabra específica en una grabación.
Use la red de reconocimiento de voz preentrenado del Repositorio de redes neuronales Wolfram para calcular la probabilidad de que una grabación contenga una palabra específica. Vea los detalles para esta red aquí.
Comience descargando y viendo una muestra en los datos entrenados de "Spoken Digit Commands" desde el Repositorio de datos Wolfram.
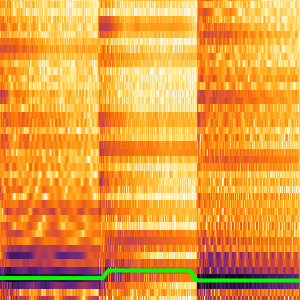
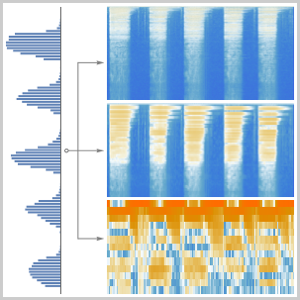
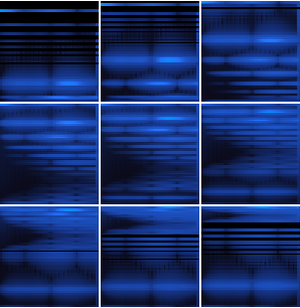
Calcule las probabilidades de cualquier letra sola en todos los tiempos usando la red.
Usted puede usar el CTCLossLayer para calcular la probabilidad logarítmica negativa de una secuencia específica de caracteres dada la salida de la red.
Calcule la probabilidad logarítmica de la transcripción siendo uno de los dígitos del 0 al 9.
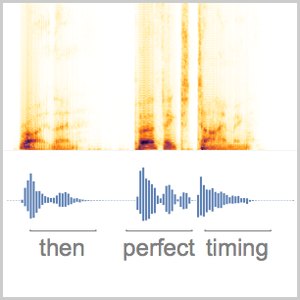
Usted puede hacer la misma operación en una muestra de audio más larga usando una ventana desplegable.
Calcule las probabilidades de cualquier letra sola en todos los tiempos usando la red.
Elija los candidatos de transcripción.
Usted puede partir las probabilidades calculadas por la red para inspeccionar los subconjuntos de la señal. La pérdida CTC puede ser calculada con respecto a todas las opciones de cada división. Esto producirá la probabilidad logarítmica de una opción específica siendo la transcripción de una división específica. BlockMap se usa para aplicar la función a particiones de la señal de audio.
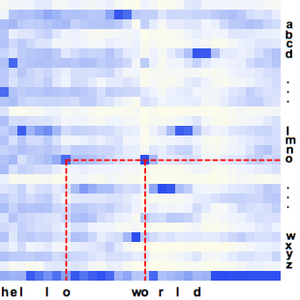
Usted ahora puede graficar las probabilidades de las tres palabras como una función de tiempo.